
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution (Paper Explained)
#ai #promptengineering #evolution
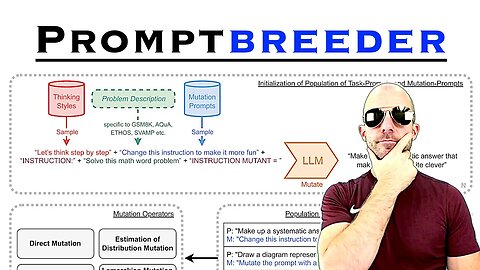
Promptbreeder is a self-improving self-referential system for automated prompt engineering. Give it a task description and a dataset, and it will automatically come up with appropriate prompts for the task. This is achieved by an evolutionary algorithm where not only the prompts, but also the mutation-prompts are improved over time in a population-based, diversity-focused approach.
OUTLINE:
0:00 - Introduction
2:10 - From manual to automated prompt engineering
10:40 - How does Promptbreeder work?
21:30 - Mutation operators
36:00 - Experimental Results
38:05 - A walk through the appendix
Paper: https://arxiv.org/abs/2309.16797
Abstract:
Popular prompt strategies like Chain-of-Thought Prompting can dramatically improve the reasoning abilities of Large Language Models (LLMs) in various domains. However, such hand-crafted prompt-strategies are often sub-optimal. In this paper, we present Promptbreeder, a general-purpose self-referential self-improvement mechanism that evolves and adapts prompts for a given domain. Driven by an LLM, Promptbreeder mutates a population of task-prompts, and subsequently evaluates them for fitness on a training set. Crucially, the mutation of these task-prompts is governed by mutation-prompts that the LLM generates and improves throughout evolution in a self-referential way. That is, Promptbreeder is not just improving task-prompts, but it is also improving the mutationprompts that improve these task-prompts. Promptbreeder outperforms state-of-the-art prompt strategies such as Chain-of-Thought and Plan-and-Solve Prompting on commonly used arithmetic and commonsense reasoning benchmarks. Furthermore, Promptbreeder is able to evolve intricate task-prompts for the challenging problem of hate speech classification.
Authors: Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, Tim Rocktäschel
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
46
views

Efficient Streaming Language Models with Attention Sinks (Paper Explained)
#llm #ai #chatgpt
How does one run inference for a generative autoregressive language model that has been trained with a fixed context size? Streaming LLMs combine the performance of windowed attention, but avoid the drop in performance by using attention sinks - an interesting phenomenon where the token at position 0 acts as an absorber of "extra" attention.
OUTLINE:
0:00 - Introduction
1:20 - What is the problem?
10:30 - The hypothesis: Attention Sinks
15:10 - Experimental evidence
18:45 - Streaming LLMs
20:45 - Semantics or position?
22:30 - Can attention sinks be learned?
27:45 - More experiments
30:10 - Comparison to Big Bird
Paper: https://arxiv.org/abs/2309.17453
Abstract:
Deploying Large Language Models (LLMs) in streaming applications such as multi-round dialogue, where long interactions are expected, is urgently needed but poses two major challenges. Firstly, during the decoding stage, caching previous tokens' Key and Value states (KV) consumes extensive memory. Secondly, popular LLMs cannot generalize to longer texts than the training sequence length. Window attention, where only the most recent KVs are cached, is a natural approach -- but we show that it fails when the text length surpasses the cache size. We observe an interesting phenomenon, namely attention sink, that keeping the KV of initial tokens will largely recover the performance of window attention. In this paper, we first demonstrate that the emergence of attention sink is due to the strong attention scores towards initial tokens as a ``sink'' even if they are not semantically important. Based on the above analysis, we introduce StreamingLLM, an efficient framework that enables LLMs trained with a finite length attention window to generalize to infinite sequence lengths without any fine-tuning. We show that StreamingLLM can enable Llama-2, MPT, Falcon, and Pythia to perform stable and efficient language modeling with up to 4 million tokens and more. In addition, we discover that adding a placeholder token as a dedicated attention sink during pre-training can further improve streaming deployment. In streaming settings, StreamingLLM outperforms the sliding window recomputation baseline by up to 22.2x speedup. Code and datasets are provided at this https URL.
Authors: Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, Mike Lewis
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
46
views

Reinforced Self-Training (ReST) for Language Modeling (Paper Explained)
#ai #rlhf #llm
ReST uses a bootsrap-like method to produce its own extended dataset and trains on ever higher-quality subsets of it to improve its own reward. The method allows for re-using the same generated data multiple times and thus has an efficiency advantage with respect to Online RL techniques like PPO.
Paper: https://arxiv.org/abs/2308.08998
Abstract:
Reinforcement learning from human feedback (RLHF) can improve the quality of large language model's (LLM) outputs by aligning them with human preferences. We propose a simple algorithm for aligning LLMs with human preferences inspired by growing batch reinforcement learning (RL), which we call Reinforced Self-Training (ReST). Given an initial LLM policy, ReST produces a dataset by generating samples from the policy, which are then used to improve the LLM policy using offline RL algorithms. ReST is more efficient than typical online RLHF methods because the training dataset is produced offline, which allows data reuse. While ReST is a general approach applicable to all generative learning settings, we focus on its application to machine translation. Our results show that ReST can substantially improve translation quality, as measured by automated metrics and human evaluation on machine translation benchmarks in a compute and sample-efficient manner.
Authors: Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, Wolfgang Macherey, Arnaud Doucet, Orhan Firat, Nando de Freitas
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
52
views
Retentive Network: A Successor to Transformer for Large Language Models (Paper Explained)
#ai #retnet #transformers
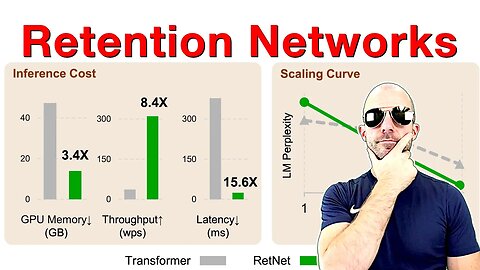
Retention is an alternative to Attention in Transformers that can both be written in a parallel and in a recurrent fashion. This means the architecture achieves training parallelism while maintaining low-cost inference. Experiments in the paper look very promising.
OUTLINE:
0:00 - Intro
2:40 - The impossible triangle
6:55 - Parallel vs sequential
15:35 - Retention mechanism
21:00 - Chunkwise and multi-scale retention
24:10 - Comparison to other architectures
26:30 - Experimental evaluation
Paper: https://arxiv.org/abs/2307.08621
Abstract:
In this work, we propose Retentive Network (RetNet) as a foundation architecture for large language models, simultaneously achieving training parallelism, low-cost inference, and good performance. We theoretically derive the connection between recurrence and attention. Then we propose the retention mechanism for sequence modeling, which supports three computation paradigms, i.e., parallel, recurrent, and chunkwise recurrent. Specifically, the parallel representation allows for training parallelism. The recurrent representation enables low-cost O(1) inference, which improves decoding throughput, latency, and GPU memory without sacrificing performance. The chunkwise recurrent representation facilitates efficient long-sequence modeling with linear complexity, where each chunk is encoded parallelly while recurrently summarizing the chunks. Experimental results on language modeling show that RetNet achieves favorable scaling results, parallel training, low-cost deployment, and efficient inference. The intriguing properties make RetNet a strong successor to Transformer for large language models. Code will be available at this https URL.
Authors: Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, Furu Wei
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
39
views
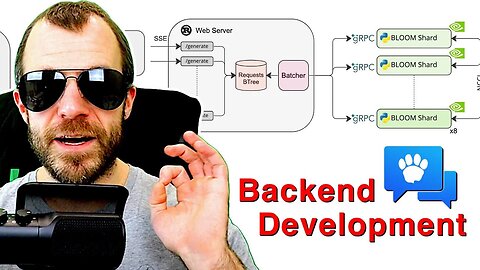
Open Assistant Inference Backend Development (Hands-On Coding)
#ai #huggingface #coding
Join me as I build streaming inference into the Hugging Face text generation server, going through cuda, python, rust, grpc, websockets, server-sent events, and more...
Original repo is here: https://github.com/huggingface/text-generation-inference
OpenAssistant repo is here: https://github.com/LAION-AI/Open-Assistant (see inference/)
Check out https://www.wandb.courses/ for free MLOps courses!
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
16
views

OpenAssistant - ChatGPT's Open Alternative (We need your help!)
#openassistant #chatgpt #ai
Help us collect data for OpenAssistant, the largest and most open alternative to ChatGPT.
https://open-assistant.io
OUTLINE:
0:00 - Intro
0:30 - The Project
2:05 - Getting to Minimum Viable Prototype
5:30 - First Tasks
10:00 - Leaderboard
11:45 - Playing the Assistant
14:40 - Tricky Facts
16:25 - What if humans had wings?
17:05 - Can foxes be tamed?
23:45 - Can zebras be tamed?
26:15 - Yo (spam)
27:00 - More tasks
29:10 - Entitled Emails
34:35 - Final Words
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
9
views
LLaMA: Open and Efficient Foundation Language Models (Paper Explained)
#ai #meta #languagemodel
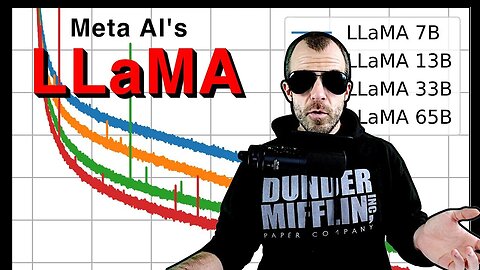
LLaMA is a series of large language models from 7B to 65B parameters, trained by Meta AI. They train for longer on more data and show that something like gpt-3 can be outperformed by significantly smaller models when trained like this. Meta also releases the trained models to the research community.
OUTLINE:
0:00 - Introduction & Paper Overview
4:30 - Rant on Open-Sourcing
8:05 - Training Data
12:40 - Training Hyperparameters
14:50 - Architecture Modifications
17:10 - Optimizer
19:40 - Efficient Implementation
26:15 - Main Results
38:00 - Some more completions
40:00 - Conclusion
Paper: https://arxiv.org/abs/2302.13971
Website: https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
Abstract:
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community.
Authors: Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
22
views

GPT-4 is here! What we know so far (Full Analysis)
#gpt4 #chatgpt #openai
References:
https://openai.com/product/gpt-4
https://openai.com/research/gpt-4
https://cdn.openai.com/papers/gpt-4.pdf
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
6
views

This ChatGPT Skill will earn you $10B (also, AI reads your mind!) | ML News
#mlnews #chatgpt #llama
ChatGPT goes around the world and is finally available via API. Stunning mind-reading performed using fMRI and Stable Diffusion. LLaMA weights leak and hilarity ensues. GTC23 is around the corner!
ERRATA: It's a 4090, not a 4090 ti 🙃
OUTLINE:
0:00 - Introduction
0:20 - GTC 23 on March 20
1:55 - ChatGPT API is out!
4:50 - OpenAI becomes more business-friendly
7:15 - OpenAI plans for AGI
10:00 - ChatGPT influencers
12:15 - Open-Source Prompting Course
12:35 - Flan UL2 20B
13:30 - LLaMA weights leaked
15:50 - Mind-Reading from fMRI
20:10 - Random News / Helpful Things
25:30 - Interview with Bryan Catanzaro
Participate in the GTC Raffle: https://ykilcher.com/gtc
References:
GTC 23 on March 20
https://www.nvidia.com/gtc/
https://ykilcher.com/gtc
ChatGPT API is out!
https://twitter.com/gdb/status/1630991925984755714
https://openai.com/blog/introducing-chatgpt-and-whisper-apis
https://twitter.com/greggyb/status/1631121912679002112
https://www.haihai.ai/chatgpt-api/
OpenAI becomes more business-friendly
https://twitter.com/sama/status/1631002519311888385
https://techcrunch.com/2023/02/21/openai-foundry-will-let-customers-buy-dedicated-capacity-to-run-its-ai-models/?guccounter=1&guce_referrer=aHR0cHM6Ly93d3cuZ29vZ2xlLmNvbS8&guce_referrer_sig=AQAAAFL1O8s22qBsEtytYZWR7O2VlTa9nAGhdZPFfeQfZCDWjkNBIac7WlDikRNLEH1tqSszUN02ouqRyyCsShDa1kQyUbiApD1IUPfgmHXZxgIMFxr8bwr8BuBa7sK55dYqMRFFbE7YILuBn_rmj7aJI1tp7GAXubODfCUaKvOkoOYj
https://www.bain.com/vector-digital/partnerships-alliance-ecosystem/openai-alliance/
OpenAI plans for AGI
https://openai.com/blog/planning-for-agi-and-beyond
ChatGPT influencers
https://www.youtube.com/watch?v=4kp7oVTu9Ck
https://www.youtube.com/watch?v=k13v8jp8H5o
https://www.linkedin.com/posts/eniascailliau_create-an-online-course-100-ai-ugcPost-7036969935796891648-H_uj/
https://www.linkedin.com/posts/linasbeliunas_must-know-ai-tools-ugcPost-7035700089947836416-Qri4/
https://twitter.com/LinusEkenstam/status/1629879567514238976
https://www.linkedin.com/posts/imarpit_50-awesome-chatgpt-prompts-ugcPost-7036905788631646209-2CU-/
Open-Source Prompting Course
https://learnprompting.org/
Flan UL2 20B
https://www.yitay.net/blog/flan-ul2-20b
https://huggingface.co/google/flan-ul2
LLaMA weights leaked
https://github.com/facebookresearch/llama/pull/73
https://github.com/facebookresearch/llama/pull/73/files#diff-b335630551682c19a781afebcf4d07bf978fb1f8ac04c6bf87428ed5106870f5
https://github.com/ChristopherKing42
https://open-assistant.io/dashboard
Mind-Reading from fMRI
https://sites.google.com/view/stablediffusion-with-brain/?s=09
https://www.nature.com/articles/s41562-022-01516-2?utm_content=animation
Random News
https://www.wired.com/story/alphabet-layoffs-hit-trash-sorting-robots/
https://huggingface.co/blog/fast-mac-diffusers
https://pyribs.org/
https://twitter.com/rowancheung/status/1630569844654460928
https://pimeyes.com/en
https://cacti-framework.github.io/
https://twitter.com/bhutanisanyam1/status/1630980866775330819
https://www.linkedin.com/in/bryancatanzaro/
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
39
views

OpenAssistant First Models are here! (Open-Source ChatGPT)
#openassistant #chatgpt #gpt4
https://open-assistant.io/chat
https://huggingface.co/OpenAssistant
https://github.com/LAION-AI/Open-Assistant
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
6
views

The biggest week in AI (GPT-4, Office Copilot, Google PaLM, Anthropic Claude & more)
#mlnews #gpt4 #copilot
Your weekly news all around the AI world
Check out W&B courses (free): https://wandb.courses/
OUTLINE:
0:00 - Intro
0:20 - GPT-4 announced!
4:30 - GigaGAN: The comeback of Generative Adversarial Networks
7:55 - ChoppedAI: AI Recipes
8:45 - Samsung accused of faking space zoom effect
14:00 - Weights & Biases courses are free
16:55 - Data Portraits
18:50 - Data2Vec 2.0
19:50 - Gated Models on Hugging Face & huggingface.js
22:05 - Visual ChatGPT
23:35 - Bing crosses 100 million daily active users
24:50 - Casual Conversations Dataset
25:50 - Anthropic AI Safety Research
27:30 - Magnushammer & more advances in AI-assisted math
30:30 - LLaMA license change PR
32:00 - Self-Instruct dataset
33:35 - PaLM-E: Multimodal Pathways
35:45 - USM: Universal Speech Model
37:25 - GILGEN: Grounded Text-to-Image
39:55 - Fruit Fly Connectome released
References:
https://www.heise.de/news/GPT-4-kommt-naechste-Woche-und-es-wird-multimodal-Vorankuendigung-von-Microsoft-7540383.html
https://mingukkang.github.io/GigaGAN/
https://www.choppedai.com/
https://www.reddit.com/r/Android/comments/11nzrb0/samsung_space_zoom_moon_shots_are_fake_and_here/
https://imgur.com/ULVX933
https://imgur.com/9XMgt06
https://imgur.com/9kichAp
https://imgur.com/RSHAz1l
https://imgur.com/PIAjVKp
https://imgur.com/xEyLajW
https://imgur.com/3STX9mZ
https://imgur.com/ifIHr3S
https://imgur.com/bXJOZgI
https://dataportraits.org/
https://arxiv.org/abs/2303.03919
https://arxiv.org/pdf/2303.03919.pdf
https://ai.facebook.com/blog/ai-self-supervised-learning-data2vec/
https://github.com/facebookresearch/fairseq/tree/main/examples/data2vec
https://huggingface.co/docs/hub/models-gated
https://huggingface.co/about
https://github.com/huggingface/huggingface.js?utm_source=pocket_reader
https://github.com/microsoft/visual-chatgpt
https://arxiv.org/abs/2303.04671
https://github.com/microsoft/visual-chatgpt/blob/main/visual_chatgpt.py
https://huggingface.co/spaces/RamAnanth1/visual-chatGPT
https://www.engadget.com/microsoft-bing-crossed-100-million-daily-active-users-080138371.html
https://ai.facebook.com/blog/casual-conversations-v2-dataset-measure-fairness/
https://ai.facebook.com/datasets/casual-conversations-v2-dataset/
https://www.anthropic.com/index/core-views-on-ai-safety
https://arxiv.org/abs/2303.04488
https://arxiv.org/pdf/2303.04488.pdf
https://arxiv.org/abs/2303.04910
https://arxiv.org/pdf/2303.04910.pdf
https://twitter.com/astro_wassim/status/1633645134934949888
https://ai.papers.bar/paper/ede58b1ebca911ed8f9c3d8021bca7c8
https://arxiv.org/pdf/2303.03192.pdf
https://www.theverge.com/2023/3/8/23629362/meta-ai-language-model-llama-leak-online-misuse
https://knightcolumbia.org/blog/the-llama-is-out-of-the-bag-should-we-expect-a-tidal-wave-of-disinformation
https://github.com/facebookresearch/llama/pull/184
https://huggingface.co/datasets/yizhongw/self_instruct
https://openai.com/policies/terms-of-use
https://palm-e.github.io/
https://pickapic.io/
https://ai.googleblog.com/2023/03/universal-speech-model-usm-state-of-art.html
https://arxiv.org/abs/2303.01037
https://github.com/BlinkDL/RWKV-LM?utm_source=pocket_reader
https://gligen.github.io/
https://github.com/microsoft/GLIP
https://arxiv.org/abs/2301.07093
https://huggingface.co/spaces/gligen/demo
https://www.sciencealert.com/the-first-ever-complete-map-of-an-insect-brain-is-truly-mesmerizing
https://en.wikipedia.org/wiki/Tidal_locking
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
41
views

OpenAssistant RELEASED! The world's best open-source Chat AI!
#openassistant #chatgpt #mlnews
Try the chat: https://open-assistant.io/chat
Homepage: https://open-assistant.io
Dataset: https://huggingface.co/datasets/OpenAssistant/oasst1
Code: https://github.com/LAION-AI/Open-Assistant
Paper (temporary): https://ykilcher.com/oa-paper
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
5
views
![[ML News] Geoff Hinton leaves Google | Google has NO MOAT | OpenAI down half a billion](https://ak2.rmbl.ws/s8/1/A/W/b/5/AWb5l.oq1b.2-small-ML-News-Geoff-Hinton-leaves.jpg)
[ML News] Geoff Hinton leaves Google | Google has NO MOAT | OpenAI down half a billion
#google #openai #mlnews
Updates from the world of Machine Learning and AI
Great AI memes here: https://twitter.com/untitled01ipynb
OUTLINE:
0:00 - Google I/O 2023: Generative AI in everything
0:20 - Anthropic announces 100k tokens context
0:35 - Intro
1:20 - Geoff Hinton leaves Google
7:00 - Google memo leaked: we have no moat
11:30 - OpenAI loses 540M
12:30 - Google AI: Product first
15:50 - Ilya Sutskever on safety vs competition
18:00 - AI works cannot be copyrighted
19:40 - OpenAI tries to trademark GPT
20:30 - StarCoder: accessible code model
21:40 - RedPyjama & OpenLlama
22:55 - Mosaic 7B model
23:50 - YoloNAS
24:10 - Mojo programming language
25:30 - Random helpful things
37:40 - DeepMind soccer robots
References:
https://twitter.com/weirddalle/status/1649908805788893185
https://www.nytimes.com/2023/05/01/technology/ai-google-chatbot-engineer-quits-hinton.html
https://www.technologyreview.com/2023/05/01/1072478/deep-learning-pioneer-geoffrey-hinton-quits-google/
https://archive.ph/TrPoH
https://twitter.com/DanHendrycks/status/1654560913939374080
https://twitter.com/ylecun/status/1654930029569101824
https://twitter.com/home
https://twitter.com/ylecun/status/1654931495419621376
https://twitter.com/pkedrosky/status/1653955254181068801
https://www.semianalysis.com/p/google-we-have-no-moat-and-neither
https://twitter.com/untitled01ipynb/media
https://www.theinformation.com/articles/openais-losses-doubled-to-540-million-as-it-developed-chatgpt
https://archive.ph/bKsdM
https://www.washingtonpost.com/technology/2023/05/04/google-ai-stop-sharing-research/
https://twitter.com/giffmana/status/1654962145707130880
https://twitter.com/Ken_Goldberg/status/1651309843804987393
https://tsdr.uspto.gov/documentviewer?caseId=sn97733259&docId=PTD20230418160641&s=09#docIndex=1&page=1
https://twitter.com/osanseviero/status/1654230764513370112
https://huggingface.co/bigcode/starcoder
https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement
https://twitter.com/hardmaru/status/1654649036333514753
https://www.together.xyz/blog/redpajama-models-v1
https://huggingface.co/togethercomputer/RedPajama-INCITE-Base-3B-v1
https://github.com/openlm-research/open_llama
https://www.mosaicml.com/blog/mpt-7b
https://github.com/Deci-AI/super-gradients/blob/master/YOLONAS.md
https://www.modular.com/mojo
https://www.aicrowd.com/challenges/hackaprompt-2023
https://learnprompting.org/
https://developer.nvidia.com/blog/nvidia-enables-trustworthy-safe-and-secure-large-language-model-conversational-systems/?ncid=prsy-552511
https://blogs.nvidia.com/blog/2023/04/25/ai-chatbot-guardrails-nemo/
https://lmql.ai/#distribution
https://github.com/gventuri/pandas-ai?utm_source=pocket_reader
https://lamini.ai/blog/introducing-lamini
https://github.com/deep-floyd/IF
https://huggingface.co/spaces/DeepFloyd/IF
https://twitter.com/FaramaFound/status/1650952295901720576
https://txt.cohere.com/embedding-archives-wikipedia/?hsa_acc=509563538&hsa_ad=242008083&hsa_cam=626636963&hsa_grp=205646033&hsa_net=linkedin&hsa_ver=3&hss_channel=lcp-24024765
https://arxiv.org/abs/2304.12210
https://github.com/h2oai/h2ogpt
https://huggingface.co/h2oai/h2ogpt-oasst1-512-20b
https://github.com/h2oai/h2o-llmstudio
https://ai.facebook.com/blog/ai-dataset-animating-kids-drawings/
https://www.camel-ai.org/
https://github.com/lightaime/camel?utm_source=pocket_reader
https://huggingface.co/Writer/camel-5b-hf
https://laion.ai/blog/paella/
https://magazine.sebastianraschka.com/p/finetuning-large-language-models
https://pickapic.io/
https://github.com/yuvalkirstain/heroku_app
https://huggingface.co/datasets/yuvalkirstain/PickaPic
https://future.snorkel.ai/poster-contest/
https://twitter.com/d_feldman/status/1649466422018318338/photo/4
https://twitter.com/DeepMind/status/1651897358894919680
https://arxiv.org/abs/2304.13653
https://twitter.com/SmokeAwayyy/status/1652712832738422784
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
28
views
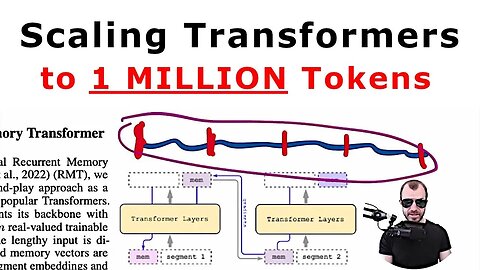
Scaling Transformer to 1M tokens and beyond with RMT (Paper Explained)
#ai #transformer #gpt4
This paper promises to scale transformers to 1 million tokens and beyond. We take a look at the technique behind it: The Recurrent Memory Transformer, and what its strenghts and weaknesses are.
OUTLINE:
0:00 - Intro
2:15 - Transformers on long sequences
4:30 - Tasks considered
8:00 - Recurrent Memory Transformer
19:40 - Experiments on scaling and attention maps
24:00 - Conclusion
Paper: https://arxiv.org/abs/2304.11062
Abstract:
This technical report presents the application of a recurrent memory to extend the context length of BERT, one of the most effective Transformer-based models in natural language processing. By leveraging the Recurrent Memory Transformer architecture, we have successfully increased the model's effective context length to an unprecedented two million tokens, while maintaining high memory retrieval accuracy. Our method allows for the storage and processing of both local and global information and enables information flow between segments of the input sequence through the use of recurrence. Our experiments demonstrate the effectiveness of our approach, which holds significant potential to enhance long-term dependency handling in natural language understanding and generation tasks as well as enable large-scale context processing for memory-intensive applications.
Authors: Aydar Bulatov, Yuri Kuratov, Mikhail S. Burtsev
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
7
views
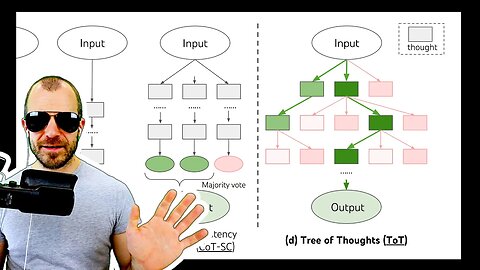
Tree of Thoughts: Deliberate Problem Solving with Large Language Models (Full Paper Review)
#gpt4 #ai #prompt
Tree-of-Thought improves prompting of large language models (LLMs) by generalizing the concept of Chain-of-Thought prompting and introduces a tree search across language model thoughts, including state evaluation and backtracking. Experiments on toy tasks show large improvements over both classic and Chain-of-Thought prompting.
OUTLINE:
0:00 - Introduction
1:20 - From Chain-of-Thought to Tree-of-Thought
11:10 - Formalizing the algorithm
16:00 - Game of 24 & Creative writing
18:30 - Crosswords
23:30 - Is this a general problem solver?
26:50 - Ablation studies
28:55 - Conclusion
Paper: https://arxiv.org/abs/2305.10601
Abstract:
Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require exploration, strategic lookahead, or where initial decisions play a pivotal role. To surmount these challenges, we introduce a new framework for language model inference, Tree of Thoughts (ToT), which generalizes over the popular Chain of Thought approach to prompting language models, and enables exploration over coherent units of text (thoughts) that serve as intermediate steps toward problem solving. ToT allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices. Our experiments show that ToT significantly enhances language models' problem-solving abilities on three novel tasks requiring non-trivial planning or search: Game of 24, Creative Writing, and Mini Crosswords. For instance, in Game of 24, while GPT-4 with chain-of-thought prompting only solved 4% of tasks, our method achieved a success rate of 74%. Code repo with all prompts: this https URL.
Authors: Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, Karthik Narasimhan
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
12
views

OpenAI suggests AI licenses (US Senate hearing on AI regulation w/ Sam Altman)
#ai #openai #gpt4
US Senate hearing on AI regulation.
MLST video on the hearing: https://www.youtube.com/watch?v=DeSXnESGxr4
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
4
views
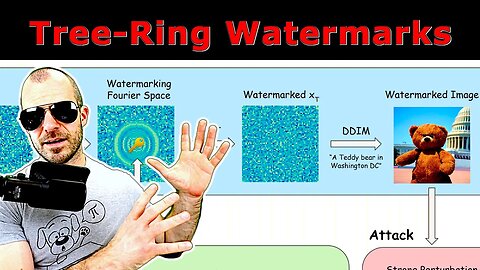
Tree-Ring Watermarks: Fingerprints for Diffusion Images that are Invisible and Robust (Explained)
#stablediffusion #ai #watermark
Watermarking the outputs of generative models is usually done as a post-processing step on the model outputs. Tree-Ring Watermarks are applied in the latent space at the beginning of a diffusion process, which makes them nearly undetectable, robust to strong distortions, and only recoverable by the model author. It is a very promising technique with applications potentially beyond watermarking itself.
OUTLINE:
0:00 - Introduction & Overview
1:30 - Why Watermarking?
4:20 - Diffusion Models Recap
13:40 - Inverting Diffusion Models
17:05 - Tree-Ring Watermarking
26:15 - Effects of Tree-Ring Watermarks
30:00 - Experimental Results
32:40 - Limitations
34:40 - Conclusion
Paper: https://arxiv.org/abs/2305.20030
Abstract:
Watermarking the outputs of generative models is a crucial technique for tracing copyright and preventing potential harm from AI-generated content. In this paper, we introduce a novel technique called Tree-Ring Watermarking that robustly fingerprints diffusion model outputs. Unlike existing methods that perform post-hoc modifications to images after sampling, Tree-Ring Watermarking subtly influences the entire sampling process, resulting in a model fingerprint that is invisible to humans. The watermark embeds a pattern into the initial noise vector used for sampling. These patterns are structured in Fourier space so that they are invariant to convolutions, crops, dilations, flips, and rotations. After image generation, the watermark signal is detected by inverting the diffusion process to retrieve the noise vector, which is then checked for the embedded signal. We demonstrate that this technique can be easily applied to arbitrary diffusion models, including text-conditioned Stable Diffusion, as a plug-in with negligible loss in FID. Our watermark is semantically hidden in the image space and is far more robust than watermarking alternatives that are currently deployed. Code is available at this https URL.
Authors: Yuxin Wen, John Kirchenbauer, Jonas Geiping, Tom Goldstein
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
21
views
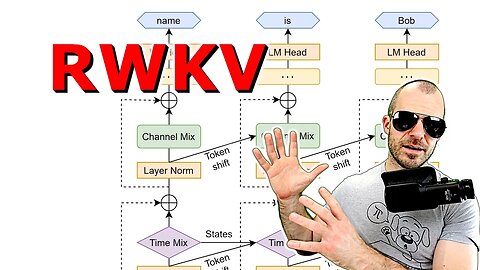
RWKV: Reinventing RNNs for the Transformer Era (Paper Explained)
#gpt4 #rwkv #transformer
We take a look at RWKV, a highly scalable architecture between Transformers and RNNs.
Fully Connected (June 7th in SF) Promo Link: https://www.fullyconnected.com/?promo=ynnc
OUTLINE:
0:00 - Introduction
1:50 - Fully Connected In-Person Conference in SF June 7th
3:00 - Transformers vs RNNs
8:00 - RWKV: Best of both worlds
12:30 - LSTMs
17:15 - Evolution of RWKV's Linear Attention
30:40 - RWKV's Layer Structure
49:15 - Time-Parallel vs Sequence Mode
53:55 - Experimental Results & Limitations
58:00 - Visualizations
1:01:40 - Conclusion
Paper: https://arxiv.org/abs/2305.13048
Code: https://github.com/BlinkDL/RWKV-LM
Abstract:
Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, which parallelizes computations during training and maintains constant computational and memory complexity during inference, leading to the first non-transformer architecture to be scaled to tens of billions of parameters. Our experiments reveal that RWKV performs on par with similarly sized Transformers, suggesting that future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling the trade-offs between computational efficiency and model performance in sequence processing tasks.
Authors: Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, Kranthi Kiran GV, Xuzheng He, Haowen Hou, Przemyslaw Kazienko, Jan Kocon, Jiaming Kong, Bartlomiej Koptyra, Hayden Lau, Krishna Sri Ipsit Mantri, Ferdinand Mom, Atsushi Saito, Xiangru Tang, Bolun Wang, Johan S. Wind, Stansilaw Wozniak, Ruichong Zhang, Zhenyuan Zhang, Qihang Zhao, Peng Zhou, Jian Zhu, Rui-Jie Zhu
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
10
views
DeepFloyd IF - Pixel-Based Text-to-Image Diffusion (w/ Authors)
#ai #diffusion #stabilityai
An interview with DeepFloyd members Misha Konstantinov and Daria Bakshandaeva on the release of the model IF, an open-source model following Google's implementation of Imagen.
References:
https://www.deepfloyd.ai/deepfloyd-if
https://huggingface.co/DeepFloyd
https://twitter.com/_gugutse_
https://twitter.com/_bra_ket
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
4
views
![[ML News] GPT-4 solves MIT Exam with 100% ACCURACY | OpenLLaMA 13B released](https://ak2.rmbl.ws/s8/1/s/m/d/5/smd5l.oq1b.2-small-ML-News-GPT-4-solves-MIT-Ex.jpg)
[ML News] GPT-4 solves MIT Exam with 100% ACCURACY | OpenLLaMA 13B released
#gpt4 #mit #ai
A new paper claims to use GPT-4 to solve 100% of a set of MIT university exercises. Some people are skeptic and their investigations reveal more than one problem with this paper...
OUTLINE:
0:00 - ChatGPT gives out Windows 10 keys
0:30 - MIT exam paper
2:50 - Prompt engineering
5:30 - Automatic grading
6:45 - Response by other MIT students
8:30 - Unsolvable questions
10:50 - Duplicates
13:30 - Cascading the heuristics
22:40 - Other problems
29:25 - OpenLLaMA 13B published
References:
https://twitter.com/immasiddtweets/status/1669721470006857729/photo/1
https://arxiv.org/abs/2306.08997
https://arxiv.org/pdf/2306.08997.pdf
https://flower-nutria-41d.notion.site/No-GPT4-can-t-ace-MIT-b27e6796ab5a48368127a98216c76864
https://github.com/idrori/MITQ/commit/3feee1026318e537c0ad27968001ef76e4a36890
https://twitter.com/hardmaru/status/1670246674760077312
https://twitter.com/giffmana/status/1670258748286472193
https://twitter.com/T3816440886465/status/1670127224131862531
https://twitter.com/qrdl/status/1669856336652414977
https://www.chegg.com/homework-help/questions-and-answers/consider-mdp-set-possible-states-mathcal-s-0-1-2-3-set-possible-actions-mathcal-b-c--rewar-q111042613
https://github.com/openlm-research/open_llama
https://huggingface.co/openlm-research/open_llama_13b
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
5
views

Recipe AI suggests FATAL CHLORINE GAS Recipe
#llm #safety #gpt4
A prime example of intellectual dishonesty of journalists and AI critics.
Article: https://gizmodo.com/paknsave-ai-savey-recipe-bot-chlorine-gas-1850725057
My Recipe AI: https://github.com/yk/recipe-ai
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
6
views

How Cyber Criminals Are Using ChatGPT (w/ Sergey Shykevich)
#cybercrime #chatgpt #security
An interview with Sergey Shykevich, Threat Intelligence Group Manager at Check Point, about how models like ChatGPT have impacted the realm of cyber crime.
https://threatmap.checkpoint.com/
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
4
views
![[ML News] LLaMA2 Released | LLMs for Robots | Multimodality on the Rise](https://ak2.rmbl.ws/s8/1/6/g/f/5/6gf5l.oq1b.2-small-ML-News-LLaMA2-Released-LLM.jpg)
[ML News] LLaMA2 Released | LLMs for Robots | Multimodality on the Rise
#mlnews #llama2 #openai
Your regular irregular update on the world of Machine Learning.
References:
https://twitter.com/ylecun/status/1681336284453781505
https://ai.meta.com/llama/
https://about.fb.com/news/2023/07/llama-2-statement-of-support/
https://247wallst.com/special-report/2023/08/12/this-is-the-biggest-social-media-platform-ranking-the-worlds-largest-networking-sites/4/
https://github.com/Alpha-VLLM/LLaMA2-Accessory
https://together.ai/blog/llama-2-7b-32k?s=09&utm_source=pocket_saves
https://github.com/imoneoi/openchat
https://twitter.com/lmsysorg/status/1686794639469371393?s=09&t=sS3awkbavmSMSmwp64Ef4A&utm_source=pocket_saves
https://huggingface.co/lmsys/vicuna-13b-v1.5-16k
https://blog.google/outreach-initiatives/public-policy/google-microsoft-openai-anthropic-frontier-model-forum/
https://www.earthdata.nasa.gov/news/impact-ibm-hls-foundation-model?utm_source=pocket_reader
https://huggingface.co/ibm-nasa-geospatial/Prithvi-100M
https://ai.meta.com/blog/generative-ai-text-images-cm3leon/
https://www.deepmind.com/blog/rt-2-new-model-translates-vision-and-language-into-action?utm_source=twitter&utm_medium=social&utm_campaign=rt2
https://arxiv.org/abs/2307.14334
https://sites.research.google/med-palm/
https://open-catalyst.metademolab.com/?utm_source=twitter&utm_medium=organic_social&utm_campaign=opencatalyst&utm_content=card
https://open-catalyst.metademolab.com/demo
https://www.anthropic.com/index/claude-2?utm_source=pocket_reader
https://claude.ai/login
https://audiocraft.metademolab.com/?utm_source=pocket_saves
https://venturebeat.com/programming-development/stability-ai-launches-stablecode-an-llm-for-code-generation/
https://stability.ai/blog/stablecode-llm-generative-ai-coding
https://twitter.com/JeffDean/status/1686806525862608896?s=09&t=LG2z9ok9QExHbSy0fvBsxA&utm_source=pocket_saves
https://sites.research.google/open-buildings/
https://twitter.com/deliprao/status/1687283117873106946?s=09&t=1NmC-B55Z8IuF_HTuGOo7w&utm_source=pocket_saves
https://arxiv.org/pdf/2308.01320.pdf
https://twitter.com/javilopen/status/1687795349719547905?utm_source=pocket_saves
https://research.nvidia.com/labs/par/Perfusion/
https://ar5iv.labs.arxiv.org/html/2307.14936
https://www.linkedin.com/feed/update/urn:li:activity:7093463974750371840/?utm_source=pocket_saves
https://huggingface.co/syzymon/long_llama_3b_instruct
https://arxiv.org/abs/2307.03170
https://dynalang.github.io/
https://github.com/mlfoundations/open_flamingo
https://twitter.com/akshay_pachaar/status/1687079353937698816?s=09&t=fos8QSCsGEEM6dMflhq0Mg&utm_source=pocket_saves
https://github.com/OpenBMB/ToolBench
https://llm-attacks.org/
https://arstechnica.com/information-technology/2023/07/openai-discontinues-its-ai-writing-detector-due-to-low-rate-of-accuracy/
https://sites.google.com/view/steve-1
https://github.com/Shalev-Lifshitz/STEVE-1
https://erichartford.com/dolphin
https://huggingface.co/ehartford/dolphin-llama-13b
https://www.mosaicml.com/blog/long-context-mpt-7b-8k
https://twitter.com/camenduru/status/1688045780244848640?s=09&t=ubJ2Qtz-TG6Xo3_GMtt2Cw&utm_source=pocket_saves
https://github.com/IDEA-Research/DWPose
https://twitter.com/tri_dao/status/1680987577913065472?s=09&t=Q181vFmM6d3nDq-5BwfDeg&utm_source=pocket_saves
https://tridao.me/publications/flash2/flash2.pdf
https://thehackernews.com/2023/07/wormgpt-new-ai-tool-allows.html
https://www.tomshardware.com/news/ai-steals-data-with-keystroke-audio
https://arxiv.org/pdf/2308.01074.pdf
https://www.foxnews.com/politics/ai-test-flight-air-force-unmanned-wingman-aircraft
https://www.theverge.com/2023/8/2/23817406/white-castle-soundhound-ai-sliders
https://www.google.com/search?sca_esv=556495916&q=food+delivery+bot+kicked&tbm=vid&source=lnms&sa=X&ved=2ahUKEwjZ6PDPrdmAAxUThf0HHWzrBGgQ0pQJegQIChAB&cshid=1691920142432720&biw=2327&bih=1180&dpr=2.2
https://www.youtube.com/watch?v=--n_NhmXnfc
https://www.thesun.co.uk/tech/20793591/coop-delivery-robots-cambridge-kicked-by-workers-tiktok/
https://ktla.com/news/local-news/food-delivery-robots-under-attack-from-vandals-thieves-local-businesses-starting-to-be-affected/
https://www.youtube.com/watch?v=xxzS9qaARv0
https://www.psypost.org/2023/08/chatgpt-is-much-better-than-humans-at-accurately-identifying-emotions-in-fictional-textual-scenarios-167380
https://www.theverge.com/2023/8/1/23815287/meta-ai-persona-generative-llama-instagram-facebook
https://www.cnbc.com/2023/07/28/microsoft-annual-report-highlights-importance-of-gpus.html
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
93
views

ChatGPT: This AI has a JAILBREAK?! (Unbelievable AI Progress)
#chatgpt #ai #openai
ChatGPT, OpenAI's newest model is a GPT-3 variant that has been fine-tuned using Reinforcement Learning from Human Feedback, and it is taking the world by storm!
Sponsor: Weights & Biases
https://wandb.me/yannic
OUTLINE:
0:00 - Intro
0:40 - Sponsor: Weights & Biases
3:20 - ChatGPT: How does it work?
5:20 - Reinforcement Learning from Human Feedback
7:10 - ChatGPT Origins: The GPT-3.5 Series
8:20 - OpenAI's strategy: Iterative Refinement
9:10 - ChatGPT's amazing capabilities
14:10 - Internals: What we know so far
16:10 - Building a virtual machine in ChatGPT's imagination (insane)
20:15 - Jailbreaks: Circumventing the safety mechanisms
29:25 - How OpenAI sees the future
References:
https://openai.com/blog/chatgpt/
https://openai.com/blog/language-model-safety-and-misuse/
https://beta.openai.com/docs/model-index-for-researchers
https://scale.com/blog/gpt-3-davinci-003-comparison#Conclusion
https://twitter.com/johnvmcdonnell/status/1598470129121374209
https://twitter.com/blennon_/status/1597374826305318912
https://twitter.com/TimKietzmann/status/1598230759118376960/photo/1
https://twitter.com/_lewtun/status/1598056075672027137/photo/2
https://twitter.com/raphaelmilliere/status/1598469100535259136
https://twitter.com/CynthiaSavard/status/1598498138658070530/photo/1
https://twitter.com/tylerangert/status/1598389755997290507/photo/1
https://twitter.com/amasad/status/1598042665375105024/photo/1
https://twitter.com/goodside/status/1598129631609380864/photo/1
https://twitter.com/moyix/status/1598081204846489600/photo/2
https://twitter.com/JusticeRage/status/1598959136531546112
https://twitter.com/yoavgo/status/1598594145605636097
https://twitter.com/EladRichardson/status/1598333315764871174
https://twitter.com/charles_irl/status/1598319027327307785/photo/4
https://twitter.com/jasondebolt/status/1598243854343606273
https://twitter.com/mattshumer_/status/1598185710166896641/photo/1
https://twitter.com/i/web/status/1598246145171804161
https://twitter.com/bleedingedgeai/status/1598378564373471232
https://twitter.com/MasterScrat/status/1598830356115124224
https://twitter.com/Sentdex/status/1598803009844256769
https://twitter.com/harrison_ritz/status/1598828017446371329
https://twitter.com/parafactual/status/1598212029479026689
https://www.engraved.blog/building-a-virtual-machine-inside/
https://twitter.com/317070
https://twitter.com/zehavoc/status/1599193444043268096
https://twitter.com/yoavgo/status/1598360581496459265
https://twitter.com/yoavgo/status/1599037412411596800
https://twitter.com/yoavgo/status/1599045344863879168
https://twitter.com/natfriedman/status/1598477452661383168
https://twitter.com/conradev/status/1598487973351362561/photo/1
https://twitter.com/zswitten/status/1598100186605441024
https://twitter.com/CatEmbedded/status/1599141379879600128/photo/2
https://twitter.com/mattshumer_/status/1599175127148949505
https://twitter.com/vaibhavk97/status/1598930958769860608/photo/1
https://twitter.com/dan_abramov/status/1598800508160024588/photo/1
https://twitter.com/MinqiJiang/status/1598832656422432768/photo/2
https://twitter.com/zswitten/status/1598088280066920453
https://twitter.com/m1guelpf/status/1598203861294252033/photo/1
https://twitter.com/SilasAlberti/status/1598257908567117825/photo/1
https://twitter.com/gf_256/status/1598962842861899776/photo/1
https://twitter.com/zswitten/status/1598088267789787136
https://twitter.com/gf_256/status/1598178469955112961/photo/1
https://twitter.com/samczsun/status/1598564871653789696/photo/1
https://twitter.com/haus_cole/status/1598541468058390534/photo/3
https://twitter.com/tailcalled/status/1599181030065246208/photo/1
https://twitter.com/pensharpiero/status/1598731292278865920
https://twitter.com/sleepdensity/status/1598233414683197441
https://twitter.com/goodside/status/1598253337400717313
https://twitter.com/Carnage4Life/status/1598332648723976193/photo/2
https://github.com/sw-yx/ai-notes/blob/main/TEXT.md#jailbreaks
https://twitter.com/dannypostmaa/status/1599352584963170309/photo/4
https://twitter.com/sama/status/1599112749833125888
https://twitter.com/sama/status/1599114807474810884
https://twitter.com/sama/status/1599461195005587456
https://twitter.com/deliprao/status/1599451192215887872
https://twitter.com/michlbrmly/status/1599168681711656961
https://twitter.com/zoink/status/1599281052115034113
Links:
https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
87
views
![[ML News] GPT-4 Rumors | AI Mind Reading | Neuron Interaction Solved | AI Theorem Proving](https://ak2.rmbl.ws/s8/1/K/8/I/a/K8Iah.oq1b.2-small-ML-News-GPT-4-Rumors-AI-Min.jpg)
[ML News] GPT-4 Rumors | AI Mind Reading | Neuron Interaction Solved | AI Theorem Proving
#ai #mlnews #gpt4
Your weekly news from the AI & Machine Learning world.
OUTLINE:
0:00 - Introduction
0:25 - AI reads brain signals to predict what you're thinking
3:00 - Closed-form solution for neuron interactions
4:15 - GPT-4 rumors
6:50 - Cerebras supercomputer
7:45 - Meta releases metagenomics atlas
9:15 - AI advances in theorem proving
10:40 - Better diffusion models with expert denoisers
12:00 - BLOOMZ & mT0
13:05 - ICLR reviewers going mad
21:40 - Scaling Transformer inference
22:10 - Infinite nature flythrough generation
23:55 - Blazing fast denoising
24:45 - Large-scale AI training with MultiRay
25:30 - arXiv to include Hugging Face spaces
26:10 - Multilingual Diffusion
26:30 - Music source separation
26:50 - Multilingual CLIP
27:20 - Drug response prediction
27:50 - Helpful Things
ERRATA:
HF did not acquire spaces, they launched spaces themselves and supported Gradio from the start. They later acquired Gradio.
References:
AI reads brain signals to predict what you're thinking
https://mind-vis.github.io/?s=09&utm_source=pocket_saves
https://neurosciencenews.com/bmi-internal-speech-21837/
Closed-form solution for neuron interactions
https://twitter.com/ramin_m_h/status/1592585672606769153/photo/1
https://github.com/raminmh/CfC
https://github.com/raminmh/CfC/blob/main/torch_cfc.py
GPT-4 rumors
https://thealgorithmicbridge.substack.com/p/gpt-4-rumors-from-silicon-valley?utm_source=pocket_reader
Cerebras supercomputer
https://www.cerebras.net/andromeda/
Meta releases metagenomics atlas
https://ai.facebook.com/blog/protein-folding-esmfold-metagenomics/
https://www.genome.gov/genetics-glossary/Metagenomics
AI advances in theorem proving
https://ai.facebook.com/blog/ai-math-theorem-proving/
https://marketplace.visualstudio.com/items?itemName=jroesch.lean
Better diffusion models with expert denoisers
https://deepimagination.cc/eDiffi/
BLOOMZ & mT0
https://arxiv.org/abs/2211.01786?utm_source=pocket_reader
https://huggingface.co/bigscience/bloomz?text=Suggest+at+least+five+related+search+terms+to+%22M%E1%BA%A1ng+neural+nh%C3%A2n+t%E1%BA%A1o%22.
ICLR reviewers going mad
https://twitter.com/XiangruTang/status/1589703605098975237?utm_source=pocket_reader
https://twitter.com/BlancheMinerva/status/1588164585961422849?utm_source=pocket_reader
https://openreview.net/forum?id=pfuqQQCB34
https://twitter.com/peter_richtarik/status/1591408710366408706?utm_source=pocket_reader
Scaling Transformer inference
https://arxiv.org/abs/2211.05102
Infinite nature flythrough generation
https://ai.googleblog.com/2022/11/infinite-nature-generating-3d.html?utm_source=pocket_reader
Blazing fast denoising
https://github.com/dome272/Paella
https://arxiv.org/abs/2211.07292
Large-scale AI training with MultiRay
https://ai.facebook.com/blog/multiray-large-scale-AI-models/
arXiv to include Hugging Face spaces
https://blog.arxiv.org/2022/11/17/discover-state-of-the-art-machine-learning-demos-on-arxiv/
Multilingual Diffusion
https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltDiffusion
Music source separation
https://github.com/facebookresearch/demucs
https://arxiv.org/abs/2211.08553
Multilingual CLIP
https://twitter.com/rom1504/status/1593719037808320513
Drug response prediction
https://phys.org/news/2022-10-ai-accurately-human-response-drug.html
https://huggingface.co/Onodofthenorth/SD_PixelArt_SpriteSheet_Generator
https://huggingface.co/spaces/ronvolutional/sd-spritesheets
https://github.com/daspartho/prompt-extend
https://huggingface.co/blog/fine-tune-whisper
https://twitter.com/CarsonKatri/status/1585412662724272128
https://github.com/carson-katri/dream-textures/
https://www.youtube.com/playlist?list=PLzvYlJMoZ02Dxtwe-MmH4nOB5jYlMGBjr
https://github.com/xl0/lovely-tensors
https://github.com/jerryjliu/gpt_index
https://colab.research.google.com/drive/1o1qYJcFeywzCIdkfKJy7cTpgZTCM2EI4
https://dagshub.com/blog/launching-data-streaming-and-upload/
https://dagshub.com/blog/build-an-end-2-end-active-learning-pipeline-part-1/
https://github.com/run-ai/genv
https://arxiv.org/abs/2210.14868
https://github.com/timeseriesAI/tsai
https://medium.com/@yangyou_berkeley/diffusion-pretraining-and-hardware-fine-tuning-can-be-almost-7x-cheaper-85e970fe207b
https://medium.com/@hpcaitech/accelerating-structure-prediction-of-protein-monomers-and-multimer-by-11-times-769715dcb5b5
https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion
https://arxiv.org/abs/2211.03726
https://github.com/Deci-AI/super-gradients
https://github.com/facebookresearch/shumai
https://github.com/huggingface/safetensors
https://github.com/google/learned_optimization/tree/main/learned_optimization/research/general_lopt
https://github.com/NVIDIA-Merlin/dataloader
https://loda-lang.org/
https://loda-lang.org/edit/
https://github.com/EelcoHoogendoorn/numga
https://arxiv.org/abs/2210.07316v1
https://huggingface.co/spaces/mteb/leaderboard
https://twitter.com/natfriedman/status/1575631194032549888
https://github.com/nat/natbot
172
views