
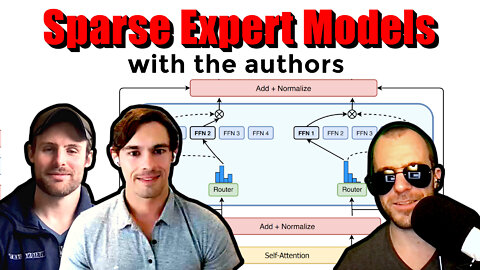
Sparse Expert Models (Switch Transformers, GLAM, and more... w/ the Authors)
#nlp #sparsity #transformers
This video is an interview with Barret Zoph and William Fedus of Google Brain about Sparse Expert Models.
Sparse Expert models have been hugely successful at distributing parts of models, mostly Transformers, across large array of machines and use a routing function to effectively route signals between them. This means that even though these models have a huge number of parameters, the computational load for a given signal does not increase because the model is only sparsely activated. Sparse expert models, such as Switch Transformers and GLAM can scale up to trillions of parameters and bring a number of desirable properties. We discuss everything from the fundamentals, history, strengths and weaknesses, up to the current state of the art of these models.
OUTLINE:
0:00 - Intro
0:30 - What are sparse expert models?
4:25 - Start of Interview
5:55 - What do you mean by sparse experts?
8:10 - How does routing work in these models?
12:10 - What is the history of sparse experts?
14:45 - What does an individual expert learn?
19:25 - When are these models appropriate?
22:30 - How comparable are sparse to dense models?
26:30 - How does the pathways system connect to this?
28:45 - What improvements did GLAM make?
31:30 - The "designing sparse experts" paper
37:45 - Can experts be frozen during training?
41:20 - Can the routing function be improved?
47:15 - Can experts be distributed beyond data centers?
50:20 - Are there sparse experts for other domains than NLP?
52:15 - Are sparse and dense models in competition?
53:35 - Where do we go from here?
56:30 - How can people get started with this?
Papers:
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (https://arxiv.org/abs/2101.03961)
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts (https://arxiv.org/abs/2112.06905)
Designing Effective Sparse Expert Models (https://arxiv.org/abs/2202.08906)
Links:
Merch: store.ykilcher.com
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
8
views

Author Interview - Transformer Memory as a Differentiable Search Index
#neuralsearch #interview #google
This is an interview with the authors Yi Tay and Don Metzler.
Paper Review Video: https://youtu.be/qlB0TPBQ7YY
Search engines work by building an index and then looking up things in it. Usually, that index is a separate data structure. In keyword search, we build and store reverse indices. In neural search, we build nearest-neighbor indices. This paper does something different: It directly trains a Transformer to return the ID of the most relevant document. No similarity search over embeddings or anything like this is performed, and no external data structure is needed, as the entire index is essentially captured by the model's weights. The paper experiments with various ways of representing documents and training the system, which works surprisingly well!
OUTLINE:
0:00 - Intro
0:50 - Start of Interview
1:30 - How did this idea start?
4:30 - How does memorization play into this?
5:50 - Why did you not compare to cross-encoders?
7:50 - Instead of the ID, could one reproduce the document itself?
10:50 - Passages vs documents
12:00 - Where can this model be applied?
14:25 - Can we make this work on large collections?
19:20 - What's up with the NQ100K dataset?
23:55 - What is going on inside these models?
28:30 - What's the smallest scale to obtain meaningful results?
30:15 - Investigating the document identifiers
34:45 - What's the end goal?
38:40 - What are the hardest problems currently?
40:40 - Final comments & how to get started
Paper: https://arxiv.org/abs/2202.06991
Abstract:
In this paper, we demonstrate that information retrieval can be accomplished with a single Transformer, in which all information about the corpus is encoded in the parameters of the model. To this end, we introduce the Differentiable Search Index (DSI), a new paradigm that learns a text-to-text model that maps string queries directly to relevant docids; in other words, a DSI model answers queries directly using only its parameters, dramatically simplifying the whole retrieval process. We study variations in how documents and their identifiers are represented, variations in training procedures, and the interplay between models and corpus sizes. Experiments demonstrate that given appropriate design choices, DSI significantly outperforms strong baselines such as dual encoder models. Moreover, DSI demonstrates strong generalization capabilities, outperforming a BM25 baseline in a zero-shot setup.
Authors: Yi Tay, Vinh Q. Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, Tal Schuster, William W. Cohen, Donald Metzler
Links:
Merch: store.ykilcher.com
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
16
views

Transformer Memory as a Differentiable Search Index (Machine Learning Research Paper Explained)
#dsi #search #google
Search engines work by building an index and then looking up things in it. Usually, that index is a separate data structure. In keyword search, we build and store reverse indices. In neural search, we build nearest-neighbor indices. This paper does something different: It directly trains a Transformer to return the ID of the most relevant document. No similarity search over embeddings or anything like this is performed, and no external data structure is needed, as the entire index is essentially captured by the model's weights. The paper experiments with various ways of representing documents and training the system, which works surprisingly well!
Sponsor: Diffgram
https://diffgram.com?ref=yannic
OUTLINE:
0:00 - Intro
0:45 - Sponsor: Diffgram
1:35 - Paper overview
3:15 - The search problem, classic and neural
8:15 - Seq2seq for directly predicting document IDs
11:05 - Differentiable search index architecture
18:05 - Indexing
25:15 - Retrieval and document representation
33:25 - Training DSI
39:15 - Experimental results
49:25 - Comments & Conclusions
Paper: https://arxiv.org/abs/2202.06991
Abstract:
In this paper, we demonstrate that information retrieval can be accomplished with a single Transformer, in which all information about the corpus is encoded in the parameters of the model. To this end, we introduce the Differentiable Search Index (DSI), a new paradigm that learns a text-to-text model that maps string queries directly to relevant docids; in other words, a DSI model answers queries directly using only its parameters, dramatically simplifying the whole retrieval process. We study variations in how documents and their identifiers are represented, variations in training procedures, and the interplay between models and corpus sizes. Experiments demonstrate that given appropriate design choices, DSI significantly outperforms strong baselines such as dual encoder models. Moreover, DSI demonstrates strong generalization capabilities, outperforming a BM25 baseline in a zero-shot setup.
Authors: Yi Tay, Vinh Q. Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, Tal Schuster, William W. Cohen, Donald Metzler
Links:
Merch: store.ykilcher.com
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
5
views
![[ML News] Google's 540B PaLM Language Model & OpenAI's DALL-E 2 Text-to-Image Revolution](https://hugh.cdn.rumble.cloud/s/s8/1/9/q/a/R/9qaRd.oq1b.2-small-ML-News-Googles-540B-PaLM-L.jpg)
[ML News] Google's 540B PaLM Language Model & OpenAI's DALL-E 2 Text-to-Image Revolution
#mlnews #palm #dalle2
Google releases PaLM and OpenAI releases DALL-E 2 (and more news).
Sponsor: Weights & BIases
Start here: https://wandb.me/yannic
Thumbnail credit: DALL-E 2 via Sam Altman
OUTLINE
0:00 - Street interview w/ random stranger
2:25 - Intro
2:50 - PaLM - Google's 540B Pathways Language Model
7:50 - Sponsor: Weights & Biases
9:10 - OpenAI releases DALL-E 2
12:05 - Open Source Datasets and Models
13:20 - Salesforce releases CodeGen
My Live Reaction to DALL-E 2: https://youtu.be/gGPv_SYVDC8
My Video on GLIDE: https://youtu.be/gwI6g1pBD84
My Video on the Pathways System: https://youtu.be/vGFaiLeoLWw
References:
PaLM - Google's 540B Pathways Language Model
https://ai.googleblog.com/2022/04/pat...
https://storage.googleapis.com/pathwa...
OpenAI releases DALL-E 2
https://openai.com/dall-e-2/
https://cdn.openai.com/papers/dall-e-...
https://www.instagram.com/openaidalle/
https://twitter.com/sama/status/15117...
https://twitter.com/sama/media
https://twitter.com/BorisMPower/statu...
https://twitter.com/ariskonstant/stat...
Open Source Datasets and Models
https://twitter.com/multimodalart/sta...
https://laion.ai/laion-5b-a-new-era-o...
https://github.com/mlfoundations/open...
Salesforce releases CodeGen
https://github.com/salesforce/CodeGen
Links:
Merch: store.ykilcher.com
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
7
views

Author Interview - Improving Intrinsic Exploration with Language Abstractions
#reinforcementlearning #ai #explained
This is an interview with Jesse Mu, first author of the paper.
Original Paper Review: https://youtu.be/NeGJAUSQEJI
Exploration is one of the oldest challenges for Reinforcement Learning algorithms, with no clear solution to date. Especially in environments with sparse rewards, agents face significant challenges in deciding which parts of the environment to explore further. Providing intrinsic motivation in form of a pseudo-reward is sometimes used to overcome this challenge, but often relies on hand-crafted heuristics, and can lead to deceptive dead-ends. This paper proposes to use language descriptions of encountered states as a method of assessing novelty. In two procedurally generated environments, they demonstrate the usefulness of language, which is in itself highly concise and abstractive, which lends itself well for this task.
OUTLINE:
0:00 - Intro
0:55 - Paper Overview
4:30 - Aren't you just adding extra data?
9:35 - Why are you splitting up the AMIGo teacher?
13:10 - How do you train the grounding network?
16:05 - What about causally structured environments?
17:30 - Highlights of the experimental results
20:40 - Why is there so much variance?
22:55 - How much does it matter that we are testing in a video game?
27:00 - How does novelty interface with the goal specification?
30:20 - The fundamental problems of exploration
32:15 - Are these algorithms subject to catastrophic forgetting?
34:45 - What current models could bring language to other environments?
40:30 - What does it take in terms of hardware?
43:00 - What problems did you encounter during the project?
46:40 - Where do we go from here?
Paper: https://arxiv.org/abs/2202.08938
Abstract:
Reinforcement learning (RL) agents are particularly hard to train when rewards are sparse. One common solution is to use intrinsic rewards to encourage agents to explore their environment. However, recent intrinsic exploration methods often use state-based novelty measures which reward low-level exploration and may not scale to domains requiring more abstract skills. Instead, we explore natural language as a general medium for highlighting relevant abstractions in an environment. Unlike previous work, we evaluate whether language can improve over existing exploration methods by directly extending (and comparing to) competitive intrinsic exploration baselines: AMIGo (Campero et al., 2021) and NovelD (Zhang et al., 2021). These language-based variants outperform their non-linguistic forms by 45-85% across 13 challenging tasks from the MiniGrid and MiniHack environment suites.
Authors: Jesse Mu, Victor Zhong, Roberta Raileanu, Minqi Jiang, Noah Goodman, Tim Rocktäschel, Edward Grefenstette
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
5
views

The Weird and Wonderful World of AI Art (w/ Author Jack Morris)
#aiart #deeplearning #clip
Since the release of CLIP, the world of AI art has seen an unprecedented level of acceleration in what's possible to do. Whereas image generation had previously been mostly in the domain of scientists, now a community of professional artists, researchers, and amateurs are sending around colab notebooks and sharing their creations via social media. How did this happen? What is going on? And where do we go from here? Jack Morris and I attempt to answer some of these questions, following his blog post "The Weird and Wonderful World of AI Art" (linked below).
OUTLINE:
0:00 - Intro
2:30 - How does one get into AI art?
5:00 - Deep Dream & Style Transfer: the early days of art in deep learning
10:50 - The advent of GANs, ArtBreeder and TikTok
19:50 - Lacking control: Pre-CLIP art
22:40 - CLIP & DALL-E
30:20 - The shift to shared colabs
34:20 - Guided diffusion models
37:20 - Prompt engineering for art models
43:30 - GLIDE
47:00 - Video production & Disco Diffusion
48:40 - Economics, money, and NFTs
54:15 - What does the future hold for AI art?
Blog post: https://jxmo.notion.site/The-Weird-an...
Jack's Blog: https://jxmo.io/
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
2
views

Improving Intrinsic Exploration with Language Abstractions (Machine Learning Paper Explained)
#reinforcementlearning #ai #explained
Exploration is one of the oldest challenges for Reinforcement Learning algorithms, with no clear solution to date. Especially in environments with sparse rewards, agents face significant challenges in deciding which parts of the environment to explore further. Providing intrinsic motivation in form of a pseudo-reward is sometimes used to overcome this challenge, but often relies on hand-crafted heuristics, and can lead to deceptive dead-ends. This paper proposes to use language descriptions of encountered states as a method of assessing novelty. In two procedurally generated environments, they demonstrate the usefulness of language, which is in itself highly concise and abstractive, which lends itself well for this task.
OUTLINE:
0:00 - Intro
1:10 - Paper Overview: Language for exploration
5:40 - The MiniGrid & MiniHack environments
7:00 - Annotating states with language
9:05 - Baseline algorithm: AMIGo
12:20 - Adding language to AMIGo
22:55 - Baseline algorithm: NovelD and Random Network Distillation
29:45 - Adding language to NovelD
31:50 - Aren't we just using extra data?
34:55 - Investigating the experimental results
40:45 - Final comments
Paper: https://arxiv.org/abs/2202.08938
Abstract:
Reinforcement learning (RL) agents are particularly hard to train when rewards are sparse. One common solution is to use intrinsic rewards to encourage agents to explore their environment. However, recent intrinsic exploration methods often use state-based novelty measures which reward low-level exploration and may not scale to domains requiring more abstract skills. Instead, we explore natural language as a general medium for highlighting relevant abstractions in an environment. Unlike previous work, we evaluate whether language can improve over existing exploration methods by directly extending (and comparing to) competitive intrinsic exploration baselines: AMIGo (Campero et al., 2021) and NovelD (Zhang et al., 2021). These language-based variants outperform their non-linguistic forms by 45-85% across 13 challenging tasks from the MiniGrid and MiniHack environment suites.
Authors: Jesse Mu, Victor Zhong, Roberta Raileanu, Minqi Jiang, Noah Goodman, Tim Rocktäschel, Edward Grefenstette
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
10
views
![[ML News] GPT-3 learns to edit | Google Pathways | Make-A-Scene | CLIP meets GamePhysics | DouBlind](https://hugh.cdn.rumble.cloud/s/s8/1/r/U/e/M/rUeMd.oq1b.2-small-ML-News-GPT-3-learns-to-edi.jpg)
[ML News] GPT-3 learns to edit | Google Pathways | Make-A-Scene | CLIP meets GamePhysics | DouBlind
#mlnews #gpt3 #pathways
Your updates on the latest and greatest from the depths of Machine Learning!
Sponsor: Weights & Biases
https://wandb.me/yannic
OUTLINE:
0:00 - Intro
0:15 - Weights & Biases Report about Reports
2:45 - GPT-3 learns to edit
6:30 - Make-A-Scene: Text-to-Image with Human Priors
8:00 - Pathways: Google's new High-Performance ML scheduler
10:45 - DouBlind: Open Peer-Review
12:45 - CLIP meets GamePhysics
14:40 - Residual Quantization pushes Image Generation SOTA
16:15 - Helpful Things
References:
Weights & Biases Report about Reports
https://wandb.ai/wandb/wandb_example/...
GPT-3 learns to edit
https://openai.com/blog/gpt-3-edit-in...
https://beta.openai.com/playground?mo...
Make-A-Scene: Text-to-Image with Human Priors
https://arxiv.org/pdf/2203.13131.pdf
https://www.youtube.com/watch?v=QLTyq...
Pathways: Google's new High-Performance ML scheduler
https://arxiv.org/pdf/2203.12533.pdf
DouBlind: Open Peer-Review
https://doublind.com/#web-intro
https://doublind.com/search?query=kil...
CLIP meets GamePhysics
https://arxiv.org/pdf/2203.11096.pdf
https://www.reddit.com/r/GamePhysics/...
https://asgaardlab.github.io/CLIPxGam...
Residual Quantization pushes Image Generation SOTA
https://arxiv.org/pdf/2203.01941.pdf
https://github.com/kakaobrain/rq-vae-...
Helpful Things
https://github.com/TDAmeritrade/stumpy
https://github.com/linkedin/fasttreeshap
https://github.com/vopani/jaxton
https://twitter.com/mark_riedl/status...
https://github.com/eilab-gt/NovGrid
https://developer.nvidia.com/isaac-gym
https://github.com/NVIDIA-Omniverse/I...
Links:
Merch: store.ykilcher.com
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
6
views

Author Interview - Memory-assisted prompt editing to improve GPT-3 after deployment
#nlp #gpt3 #prompt
This is an interview with the authors of this work, Aman Madaan and Niket Tandon.
Large language models such as GPT-3 have enabled many breakthroughs and new applications recently, but they come with an important downside: Training them is very expensive, and even fine-tuning is often difficult. This paper presents an adaptive method to improve performance of such models after deployment, without ever changing the model itself. This is done by maintaining a memory of interactions and then dynamically adapting new prompts by augmenting them with memory content. This has many applications, from non-intrusive fine-tuning to personalization.
OUTLINE:
0:00 - Intro
0:45 - Paper Overview
2:00 - What was your original motivation?
4:20 - There is an updated version of the paper!
9:00 - Have you studied this on real-world users?
12:10 - How does model size play into providing feedback?
14:10 - Can this be used for personalization?
16:30 - Discussing experimental results
17:45 - Can this be paired with recommender systems?
20:00 - What are obvious next steps to make the system more powerful?
23:15 - Clarifying the baseline methods
26:30 - Exploring cross-lingual customization
31:00 - Where did the idea for the clarification prompt come from?
33:05 - What did not work out during this project?
34:45 - What did you learn about interacting with large models?
37:30 - Final thoughts
Paper: https://arxiv.org/abs/2201.06009
Code & Data: https://github.com/madaan/memprompt
Abstract:
Large LMs such as GPT-3 are powerful, but can commit mistakes that are obvious to humans. For example, GPT-3 would mistakenly interpret "What word is similar to good?" to mean a homonym, while the user intended a synonym. Our goal is to effectively correct such errors via user interactions with the system but without retraining, which will be prohibitively costly. We pair GPT-3 with a growing memory of recorded cases where the model misunderstood the user's intents, along with user feedback for clarification. Such a memory allows our system to produce enhanced prompts for any new query based on the user feedback for error correction on similar cases in the past. On four tasks (two lexical tasks, two advanced ethical reasoning tasks), we show how a (simulated) user can interactively teach a deployed GPT-3, substantially increasing its accuracy over the queries with different kinds of misunderstandings by the GPT-3. Our approach is a step towards the low-cost utility enhancement for very large pre-trained LMs. All the code and data is available at this https URL.
Authors: Aman Madaan, Niket Tandon, Peter Clark, Yiming Yang
Links:
Merch: store.ykilcher.com
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
22
views
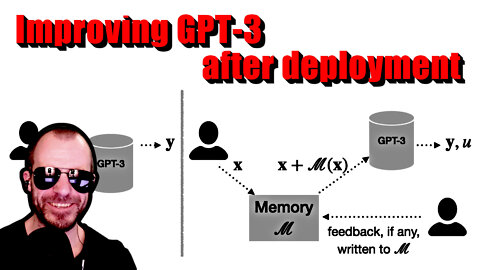
Memory-assisted prompt editing to improve GPT-3 after deployment (Machine Learning Paper Explained)
#nlp #gpt3 #prompt
Large language models such as GPT-3 have enabled many breakthroughs and new applications recently, but they come with an important downside: Training them is very expensive, and even fine-tuning is often difficult. This paper presents an adaptive method to improve performance of such models after deployment, without ever changing the model itself. This is done by maintaining a memory of interactions and then dynamically adapting new prompts by augmenting them with memory content. This has many applications, from non-intrusive fine-tuning to personalization.
Sponsor: Introduction to Graph Neural Networks Course
https://www.graphneuralnets.com/p/int...
OUTLINE:
0:00 - Intro
0:40 - Sponsor: Introduction to GNNs Course (link in description)
1:30 - Paper Overview: Improve GPT-3 after deployment via user feedback
5:30 - Proposed memory-based architecture
13:00 - A detailed look at the components
15:00 - Example tasks
24:30 - My concerns with the example setup
26:20 - Baselines used for comparison
29:50 - Experimental Results
34:20 - Conclusion & Comments
Paper: https://arxiv.org/abs/2201.06009
Code & Data: https://github.com/madaan/memprompt
Abstract:
Large LMs such as GPT-3 are powerful, but can commit mistakes that are obvious to humans. For example, GPT-3 would mistakenly interpret "What word is similar to good?" to mean a homonym, while the user intended a synonym. Our goal is to effectively correct such errors via user interactions with the system but without retraining, which will be prohibitively costly. We pair GPT-3 with a growing memory of recorded cases where the model misunderstood the user's intents, along with user feedback for clarification. Such a memory allows our system to produce enhanced prompts for any new query based on the user feedback for error correction on similar cases in the past. On four tasks (two lexical tasks, two advanced ethical reasoning tasks), we show how a (simulated) user can interactively teach a deployed GPT-3, substantially increasing its accuracy over the queries with different kinds of misunderstandings by the GPT-3. Our approach is a step towards the low-cost utility enhancement for very large pre-trained LMs. All the code and data is available at this https URL.
Authors: Aman Madaan, Niket Tandon, Peter Clark, Yiming Yang
Links:
Merch: store.ykilcher.com
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
13
views
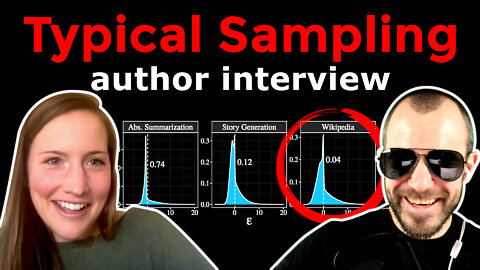
Author Interview - Typical Decoding for Natural Language Generation
#deeplearning #nlp #sampling
This is an interview with first author Clara Meister.
Paper review video hereé https://youtu.be/_EDr3ryrT_Y
Modern language models like T5 or GPT-3 achieve remarkably low perplexities on both training and validation data, yet when sampling from their output distributions, the generated text often seems dull and uninteresting. Various workarounds have been proposed, such as top-k sampling and nucleus sampling, but while these manage to somewhat improve the generated samples, they are hacky and unfounded. This paper introduces typical sampling, a new decoding method that is principled, effective, and can be implemented efficiently. Typical sampling turns away from sampling purely based on likelihood and explicitly finds a trade-off between generating high-probability samples and generating high-information samples. The paper connects typical sampling to psycholinguistic theories on human speech generation, and shows experimentally that typical sampling achieves much more diverse and interesting results than any of the current methods.
Sponsor: Introduction to Graph Neural Networks Course
https://www.graphneuralnets.com/p/int...
OUTLINE:
0:00 - Intro
0:35 - Sponsor: Introduction to GNNs Course (link in description)
1:30 - Why does sampling matter?
5:40 - What is a "typical" message?
8:35 - How do humans communicate?
10:25 - Why don't we just sample from the model's distribution?
15:30 - What happens if we condition on the information to transmit?
17:35 - Does typical sampling really represent human outputs?
20:55 - What do the plots mean?
31:00 - Diving into the experimental results
39:15 - Are our training objectives wrong?
41:30 - Comparing typical sampling to top-k and nucleus sampling
44:50 - Explaining arbitrary engineering choices
47:20 - How can people get started with this?
Paper: https://arxiv.org/abs/2202.00666
Code: https://github.com/cimeister/typical-...
Abstract:
Despite achieving incredibly low perplexities on myriad natural language corpora, today's language models still often underperform when used to generate text. This dichotomy has puzzled the language generation community for the last few years. In this work, we posit that the abstraction of natural language as a communication channel (à la Shannon, 1948) can provide new insights into the behaviors of probabilistic language generators, e.g., why high-probability texts can be dull or repetitive. Humans use language as a means of communicating information, and do so in a simultaneously efficient and error-minimizing manner; they choose each word in a string with this (perhaps subconscious) goal in mind. We propose that generation from probabilistic models should mimic this behavior. Rather than always choosing words from the high-probability region of the distribution--which have a low Shannon information content--we sample from the set of words with information content close to the conditional entropy of our model, i.e., close to the expected information content. This decision criterion can be realized through a simple and efficient implementation, which we call typical sampling. Automatic and human evaluations show that, in comparison to nucleus and top-k sampling, typical sampling offers competitive performance in terms of quality while consistently reducing the number of degenerate repetitions.
Authors: Clara Meister, Tiago Pimentel, Gian Wiher, Ryan Cotterell
Links:
Merch: store.ykilcher.com
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
19
views
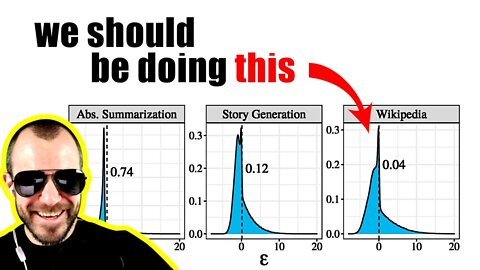
Typical Decoding for Natural Language Generation (Get more human-like outputs from language models!)
#deeplearning #nlp #sampling
Modern language models like T5 or GPT-3 achieve remarkably low perplexities on both training and validation data, yet when sampling from their output distributions, the generated text often seems dull and uninteresting. Various workarounds have been proposed, such as top-k sampling and nucleus sampling, but while these manage to somewhat improve the generated samples, they are hacky and unfounded. This paper introduces typical sampling, a new decoding method that is principled, effective, and can be implemented efficiently. Typical sampling turns away from sampling purely based on likelihood and explicitly finds a trade-off between generating high-probability samples and generating high-information samples. The paper connects typical sampling to psycholinguistic theories on human speech generation, and shows experimentally that typical sampling achieves much more diverse and interesting results than any of the current methods.
Sponsor: Fully Connected by Weights & Biases
https://wandb.ai/fully-connected
OUTLINE:
0:00 - Intro
1:50 - Sponsor: Fully Connected by Weights & Biases
4:10 - Paper Overview
7:40 - What's the problem with sampling?
11:45 - Beam Search: The good and the bad
14:10 - Top-k and Nucleus Sampling
16:20 - Why the most likely things might not be the best
21:30 - The expected information content of the next word
25:00 - How to trade off information and likelihood
31:25 - Connections to information theory and psycholinguistics
36:40 - Introducing Typical Sampling
43:00 - Experimental Evaluation
44:40 - My thoughts on this paper
Paper: https://arxiv.org/abs/2202.00666
Code: https://github.com/cimeister/typical-...
Abstract:
Despite achieving incredibly low perplexities on myriad natural language corpora, today's language models still often underperform when used to generate text. This dichotomy has puzzled the language generation community for the last few years. In this work, we posit that the abstraction of natural language as a communication channel (à la Shannon, 1948) can provide new insights into the behaviors of probabilistic language generators, e.g., why high-probability texts can be dull or repetitive. Humans use language as a means of communicating information, and do so in a simultaneously efficient and error-minimizing manner; they choose each word in a string with this (perhaps subconscious) goal in mind. We propose that generation from probabilistic models should mimic this behavior. Rather than always choosing words from the high-probability region of the distribution--which have a low Shannon information content--we sample from the set of words with information content close to the conditional entropy of our model, i.e., close to the expected information content. This decision criterion can be realized through a simple and efficient implementation, which we call typical sampling. Automatic and human evaluations show that, in comparison to nucleus and top-k sampling, typical sampling offers competitive performance in terms of quality while consistently reducing the number of degenerate repetitions.
Authors: Clara Meister, Tiago Pimentel, Gian Wiher, Ryan Cotterell
Links:
Merch: store.ykilcher.com
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
5
views

One Model For All The Tasks - BLIP (Author Interview)
#blip #interview #salesforce
Paper Review Video: https://youtu.be/X2k7n4FuI7c
Sponsor: Assembly AI
https://www.assemblyai.com/?utm_sourc...
This is an interview with Junnan Li and Dongxu Li, authors of BLIP and members of Salesforce research.
Cross-modal pre-training has been all the rage lately in deep learning, especially training vision and language models together. However, there are a number of issues, such as low quality datasets that limit the performance of any model trained on it, and also the fact that pure contrastive pre-training cannot be easily fine-tuned for most downstream tasks. BLIP unifies different tasks and objectives in a single pre-training run and achieves a much more versatile model, which the paper immediately uses to create, filter, clean and thus bootstrap its own dataset to improve performance even more!
OUTLINE:
0:00 - Intro
0:40 - Sponsor: Assembly AI
1:30 - Start of Interview
2:30 - What's the pitch?
4:40 - How did data bootstrapping come into the project?
7:10 - How big of a problem is data quality?
11:10 - Are the captioning & filtering models biased towards COCO data?
14:40 - Could the data bootstrapping be done multiple times?
16:20 - What was the evolution of the BLIP architecture?
21:15 - Are there additional benefits to adding language modelling?
23:50 - Can we imagine a modular future for pre-training?
29:45 - Diving into the experimental results
42:40 - What did and did not work out during the research?
45:00 - How is research life at Salesforce?
46:45 - Where do we go from here?
Paper: https://arxiv.org/abs/2201.12086
Code: https://github.com/salesforce/BLIP
Demo: https://huggingface.co/spaces/Salesfo...
Abstract:
Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has been largely achieved by scaling up the dataset with noisy image-text pairs collected from the web, which is a suboptimal source of supervision. In this paper, we propose BLIP, a new VLP framework which transfers flexibly to both vision-language understanding and generation tasks. BLIP effectively utilizes the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones. We achieve state-of-the-art results on a wide range of vision-language tasks, such as image-text retrieval (+2.7% in average recall@1), image captioning (+2.8% in CIDEr), and VQA (+1.6% in VQA score). BLIP also demonstrates strong generalization ability when directly transferred to video-language tasks in a zero-shot manner. Code, models, and datasets are released at this https URL.
Authors: Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
26
views
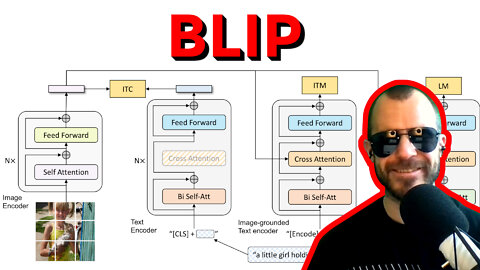
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding&Generation
#blip #review #ai
Cross-modal pre-training has been all the rage lately in deep learning, especially training vision and language models together. However, there are a number of issues, such as low quality datasets that limit the performance of any model trained on it, and also the fact that pure contrastive pre-training cannot be easily fine-tuned for most downstream tasks. BLIP unifies different tasks and objectives in a single pre-training run and achieves a much more versatile model, which the paper immediately uses to create, filter, clean and thus bootstrap its own dataset to improve performance even more!
Sponsor: Zeta Alpha
https://zeta-alpha.com
Use code YANNIC for 20% off!
OUTLINE:
0:00 - Intro
0:50 - Sponsor: Zeta Alpha
3:40 - Paper Overview
6:40 - Vision-Language Pre-Training
11:15 - Contributions of the paper
14:30 - Model architecture: many parts for many tasks
19:50 - How data flows in the model
26:50 - Parameter sharing between the modules
29:45 - Captioning & Filtering bootstrapping
41:10 - Fine-tuning the model for downstream tasks
Paper: https://arxiv.org/abs/2201.12086
Code: https://github.com/salesforce/BLIP
Demo: https://huggingface.co/spaces/Salesfo...
Abstract:
Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has been largely achieved by scaling up the dataset with noisy image-text pairs collected from the web, which is a suboptimal source of supervision. In this paper, we propose BLIP, a new VLP framework which transfers flexibly to both vision-language understanding and generation tasks. BLIP effectively utilizes the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones. We achieve state-of-the-art results on a wide range of vision-language tasks, such as image-text retrieval (+2.7% in average recall@1), image captioning (+2.8% in CIDEr), and VQA (+1.6% in VQA score). BLIP also demonstrates strong generalization ability when directly transferred to video-language tasks in a zero-shot manner. Code, models, and datasets are released at this https URL.
Authors: Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
22
views
![[ML News] AI Threatens Biological Arms Race](https://hugh.cdn.rumble.cloud/s/s8/1/X/W/Y/A/XWYAd.oq1b.2-small-ML-News-AI-Threatens-Biolog.jpg)
[ML News] AI Threatens Biological Arms Race
#mlnews #gtc22 #ithaca
GTC Registration Link: https://ykilcher.com/gtc
Your regular updates on what's going on in the ML world!
OUTLINE:
0:00 - Intro
0:20 - Register to Nvidia GTC and win a 3090!
4:15 - DeepMind's Ithaca deciphers Lost Ancient Texts
6:45 - Drug discovery model turns toxic
10:00 - Gary Marcus: Deep Learning is hitting a wall
19:40 - GopherCite: Backing up answers with citations
22:40 - Yoshua Bengio appointed knight of the legion of honour
23:00 - Meta AI tags parody account of Yoshua Bengio
23:40 - Building games using just natural language
24:55 - YOU.com adds writing assistant
25:45 - Horace He: How to brrr
26:35 - Karpathy: Reproducing Yann LeCun's 1989 paper
27:50 - Pig grunt emotion classifier
28:20 - AI annotates protein domain functions
29:40 - Atwood & Carmack: 10k self-driving car bet
30:50 - Helpful Things
References:
Register to GTC and win a 3090!
https://twitter.com/NVIDIAEU/status/1...
https://www.nvidia.com/gtc/keynote/?n...
https://www.nvidia.com/gtc/?ncid=ref-...
https://www.nvidia.com/gtc/keynote/
https://www.nvidia.com/gtc/training/
https://developer.nvidia.com/nvidia-o...
DeepMind deciphers Lost Ancient Texts
https://deepmind.com/blog/article/Pre...
https://www.nature.com/articles/s4158...
https://github.com/deepmind/ithaca
https://ithaca.deepmind.com/?job=eyJy...
Drug discovery model turns toxic
https://www.theverge.com/2022/3/17/22...
https://www.nature.com/articles/s4225...
Gary Marcus: Deep Learning is hitting a wall
https://nautil.us/deep-learning-is-hi...
https://www.youtube.com/watch?v=fVkXE...
GopherCite: Backing up answers with citations
https://deepmind.com/research/publica...
Yoshua Bengio appointed knight of the legion of honour
https://mila.quebec/en/professor-yosh...
Meta AI tags parody account
https://twitter.com/MetaAI/status/150...
Building games using just natural language
https://andrewmayneblog.wordpress.com...
YOU.com adds writing assistant
https://you.com/search?q=how%20to%20w...
Horace He: How to brrr
https://horace.io/brrr_intro.html
Karpathy: Reproducing Yann LeCun's 1989 paper
https://karpathy.github.io/2022/03/14...
Pig grunt emotion classifier
https://science.ku.dk/english/press/n...
AI annotates protein domain functions
https://ai.googleblog.com/2022/03/usi...
https://google-research.github.io/pro...
Atwood & Carmack: 10k self-driving car bet
https://blog.codinghorror.com/the-203...
Helpful Things
https://github.com/recognai/rubrix
https://twitter.com/taiyasaki/status/...
https://github.com/mosaicml/composer?...
https://mujoco.org/
https://mujoco.readthedocs.io/en/late...
https://github.com/deepmind/mctx?utm_...
https://padl.ai/
https://github.com/LaihoE/did-it-spill
https://pytorch.org/blog/pytorch-1.11...
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
20
views
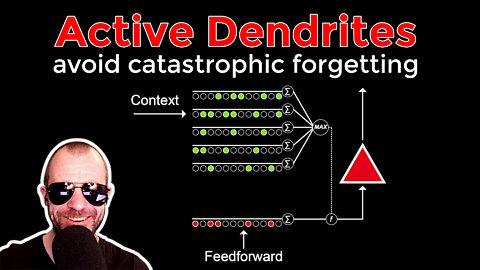
Avoiding Catastrophe: Active Dendrites Enable Multi-Task Learning in Dynamic Environments (Review)
#multitasklearning #biology #neuralnetworks
Catastrophic forgetting is a big problem in mutli-task and continual learning. Gradients of different objectives tend to conflict, and new tasks tend to override past knowledge. In biological neural networks, each neuron carries a complex network of dendrites that mitigate such forgetting by recognizing the context of an input signal. This paper introduces Active Dendrites, which carries over the principle of context-sensitive gating by dendrites into the deep learning world. Various experiments show the benefit in combatting catastrophic forgetting, while preserving sparsity and limited parameter counts.
OUTLINE:
0:00 - Introduction
1:20 - Paper Overview
3:15 - Catastrophic forgetting in continuous and multi-task learning
9:30 - Dendrites in biological neurons
16:55 - Sparse representations in biology
18:35 - Active dendrites in deep learning
34:15 - Experiments on multi-task learning
39:00 - Experiments in continual learning and adaptive prototyping
49:20 - Analyzing the inner workings of the algorithm
53:30 - Is this the same as just training a larger network?
59:15 - How does this relate to attention mechanisms?
1:02:55 - Final thoughts and comments
Paper: https://arxiv.org/abs/2201.00042
Blog: https://numenta.com/blog/2021/11/08/c...
ERRATA:
- I was made aware of this by https://twitter.com/ChainlessCoder: "That axon you showed of the pyramidal neuron, is actually the apical dendrite of the neuron". Sorry, my bad :)
Abstract:
A key challenge for AI is to build embodied systems that operate in dynamically changing environments. Such systems must adapt to changing task contexts and learn continuously. Although standard deep learning systems achieve state of the art results on static benchmarks, they often struggle in dynamic scenarios. In these settings, error signals from multiple contexts can interfere with one another, ultimately leading to a phenomenon known as catastrophic forgetting. In this article we investigate biologically inspired architectures as solutions to these problems. Specifically, we show that the biophysical properties of dendrites and local inhibitory systems enable networks to dynamically restrict and route information in a context-specific manner. Our key contributions are as follows. First, we propose a novel artificial neural network architecture that incorporates active dendrites and sparse representations into the standard deep learning framework. Next, we study the performance of this architecture on two separate benchmarks requiring task-based adaptation: Meta-World, a multi-task reinforcement learning environment where a robotic agent must learn to solve a variety of manipulation tasks simultaneously; and a continual learning benchmark in which the model's prediction task changes throughout training. Analysis on both benchmarks demonstrates the emergence of overlapping but distinct and sparse subnetworks, allowing the system to fluidly learn multiple tasks with minimal forgetting. Our neural implementation marks the first time a single architecture has achieved competitive results on both multi-task and continual learning settings. Our research sheds light on how biological properties of neurons can inform deep learning systems to address dynamic scenarios that are typically impossible for traditional ANNs to solve.
Authors: Abhiram Iyer, Karan Grewal, Akash Velu, Lucas Oliveira Souza, Jeremy Forest, Subutai Ahmad
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
23
views

Active Dendrites avoid catastrophic forgetting - Interview with the Authors
#multitasklearning #biology #neuralnetworks
This is an interview with the paper's authors: Abhiram Iyer, Karan Grewal, and Akash Velu!
Paper Review Video: https://youtu.be/O_dJ31T01i8
Check out Zak's course on Graph Neural Networks (discount with this link): https://www.graphneuralnets.com/p/int...
Catastrophic forgetting is a big problem in mutli-task and continual learning. Gradients of different objectives tend to conflict, and new tasks tend to override past knowledge. In biological neural networks, each neuron carries a complex network of dendrites that mitigate such forgetting by recognizing the context of an input signal. This paper introduces Active Dendrites, which carries over the principle of context-sensitive gating by dendrites into the deep learning world. Various experiments show the benefit in combatting catastrophic forgetting, while preserving sparsity and limited parameter counts.
OUTLINE:
0:00 - Intro
0:55 - Sponsor: GNN Course
2:30 - How did the idea come to be?
7:05 - What roles do the different parts of the method play?
8:50 - What was missing in the paper review?
10:35 - Are biological concepts viable if we still have backprop?
11:50 - How many dendrites are necessary?
14:10 - Why is there a plateau in the sparsity plot?
20:50 - How does task difficulty play into the algorithm?
24:10 - Why are there different setups in the experiments?
30:00 - Is there a place for unsupervised pre-training?
32:50 - How can we apply the online prototyping to more difficult tasks?
37:00 - What did not work out during the project?
41:30 - How do you debug a project like this?
47:10 - How is this related to other architectures?
51:10 - What other things from neuroscience are to be included?
55:50 - Don't miss the awesome ending :)
Paper: https://arxiv.org/abs/2201.00042
Blog: https://numenta.com/blog/2021/11/08/c...
Link to the GNN course (with discount): https://www.graphneuralnets.com/p/int...
Abstract:
A key challenge for AI is to build embodied systems that operate in dynamically changing environments. Such systems must adapt to changing task contexts and learn continuously. Although standard deep learning systems achieve state of the art results on static benchmarks, they often struggle in dynamic scenarios. In these settings, error signals from multiple contexts can interfere with one another, ultimately leading to a phenomenon known as catastrophic forgetting. In this article we investigate biologically inspired architectures as solutions to these problems. Specifically, we show that the biophysical properties of dendrites and local inhibitory systems enable networks to dynamically restrict and route information in a context-specific manner. Our key contributions are as follows. First, we propose a novel artificial neural network architecture that incorporates active dendrites and sparse representations into the standard deep learning framework. Next, we study the performance of this architecture on two separate benchmarks requiring task-based adaptation: Meta-World, a multi-task reinforcement learning environment where a robotic agent must learn to solve a variety of manipulation tasks simultaneously; and a continual learning benchmark in which the model's prediction task changes throughout training. Analysis on both benchmarks demonstrates the emergence of overlapping but distinct and sparse subnetworks, allowing the system to fluidly learn multiple tasks with minimal forgetting. Our neural implementation marks the first time a single architecture has achieved competitive results on both multi-task and continual learning settings. Our research sheds light on how biological properties of neurons can inform deep learning systems to address dynamic scenarios that are typically impossible for traditional ANNs to solve.
Authors: Abhiram Iyer, Karan Grewal, Akash Velu, Lucas Oliveira Souza, Jeremy Forest, Subutai Ahmad
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
34
views

Author Interview - VOS: Learning What You Don't Know by Virtual Outlier Synthesis
#deeplearning #objectdetection #outliers
An interview with the authors of "Virtual Outlier Synthesis".
Watch the paper review video here: https://youtu.be/i-J4T3uLC9M
Outliers are data points that are highly unlikely to be seen in the training distribution, and therefore deep neural networks have troubles when dealing with them. Many approaches to detecting outliers at inference time have been proposed, but most of them show limited success. This paper presents Virtual Outlier Synthesis, which is a method that pairs synthetic outliers, forged in the latent space, with an energy-based regularization of the network at training time. The result is a deep network that can reliably detect outlier datapoints during inference with minimal overhead.
OUTLINE:
0:00 - Intro
2:20 - What was the motivation behind this paper?
5:30 - Why object detection?
11:05 - What's the connection to energy-based models?
12:15 - Is a Gaussian mixture model appropriate for high-dimensional data?
16:15 - What are the most important components of the method?
18:30 - What are the downstream effects of the regularizer?
22:00 - Are there severe trade-offs to outlier detection?
23:55 - Main experimental takeaways?
26:10 - Why do outlier detection in the last layer?
30:20 - What does it take to finish a research projects successfully?
Paper: https://arxiv.org/abs/2202.01197
Code: https://github.com/deeplearning-wisc/vos
Abstract:
Out-of-distribution (OOD) detection has received much attention lately due to its importance in the safe deployment of neural networks. One of the key challenges is that models lack supervision signals from unknown data, and as a result, can produce overconfident predictions on OOD data. Previous approaches rely on real outlier datasets for model regularization, which can be costly and sometimes infeasible to obtain in practice. In this paper, we present VOS, a novel framework for OOD detection by adaptively synthesizing virtual outliers that can meaningfully regularize the model's decision boundary during training. Specifically, VOS samples virtual outliers from the low-likelihood region of the class-conditional distribution estimated in the feature space. Alongside, we introduce a novel unknown-aware training objective, which contrastively shapes the uncertainty space between the ID data and synthesized outlier data. VOS achieves state-of-the-art performance on both object detection and image classification models, reducing the FPR95 by up to 7.87% compared to the previous best method. Code is available at this https URL.
Authors: Xuefeng Du, Zhaoning Wang, Mu Cai, Yixuan Li
Links:
Merch: store.ykilcher.com
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
23
views
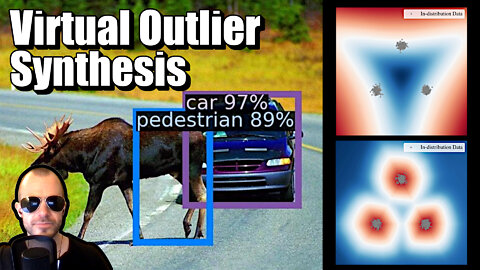
VOS: Learning What You Don't Know by Virtual Outlier Synthesis (Paper Explained)
#vos #outliers #deeplearning
Sponsor: Assembly AI
Check them out here: https://www.assemblyai.com/?utm_sourc...
Outliers are data points that are highly unlikely to be seen in the training distribution, and therefore deep neural networks have troubles when dealing with them. Many approaches to detecting outliers at inference time have been proposed, but most of them show limited success. This paper presents Virtual Outlier Synthesis, which is a method that pairs synthetic outliers, forged in the latent space, with an energy-based regularization of the network at training time. The result is a deep network that can reliably detect outlier datapoints during inference with minimal overhead.
OUTLINE:
0:00 - Intro
2:00 - Sponsor: Assembly AI (Link below)
4:05 - Paper Overview
6:45 - Where do traditional classifiers fail?
11:00 - How object detectors work
17:00 - What are virtual outliers and how are they created?
24:00 - Is this really an appropriate model for outliers?
26:30 - How virtual outliers are used during training
34:00 - Plugging it all together to detect outliers
Paper: https://arxiv.org/abs/2202.01197
Code: https://github.com/deeplearning-wisc/vos
Abstract:
Out-of-distribution (OOD) detection has received much attention lately due to its importance in the safe deployment of neural networks. One of the key challenges is that models lack supervision signals from unknown data, and as a result, can produce overconfident predictions on OOD data. Previous approaches rely on real outlier datasets for model regularization, which can be costly and sometimes infeasible to obtain in practice. In this paper, we present VOS, a novel framework for OOD detection by adaptively synthesizing virtual outliers that can meaningfully regularize the model's decision boundary during training. Specifically, VOS samples virtual outliers from the low-likelihood region of the class-conditional distribution estimated in the feature space. Alongside, we introduce a novel unknown-aware training objective, which contrastively shapes the uncertainty space between the ID data and synthesized outlier data. VOS achieves state-of-the-art performance on both object detection and image classification models, reducing the FPR95 by up to 7.87% compared to the previous best method. Code is available at this https URL.
Authors: Xuefeng Du, Zhaoning Wang, Mu Cai, Yixuan Li
Links:
Merch: store.ykilcher.com
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
25
views

Spurious normativity enhances learning of compliance and enforcement behavior in artificial agents
#deepmind #rl #society
This is an in-depth paper review, followed by an interview with the papers' authors!
Society is ruled by norms, and most of these norms are very useful, such as washing your hands before cooking. However, there also exist plenty of social norms which are essentially arbitrary, such as what hairstyles are acceptable, or what words are rude. These are called "silly rules". This paper uses multi-agent reinforcement learning to investigate why such silly rules exist. Their results indicate a plausible mechanism, by which the existence of silly rules drastically speeds up the agents' acquisition of the skill of enforcing rules, which generalizes well, and therefore a society that has silly rules will be better at enforcing rules in general, leading to faster adaptation in the face of genuinely useful norms.
OUTLINE:
0:00 - Intro
3:00 - Paper Overview
5:20 - Why are some social norms arbitrary?
11:50 - Reinforcement learning environment setup
20:00 - What happens if we introduce a "silly" rule?
25:00 - Experimental Results: how silly rules help society
30:10 - Isolated probing experiments
34:30 - Discussion of the results
37:30 - Start of Interview
39:30 - Where does the research idea come from?
44:00 - What is the purpose behind this research?
49:20 - Short recap of the mechanics of the environment
53:00 - How much does such a closed system tell us about the real world?
56:00 - What do the results tell us about silly rules?
1:01:00 - What are these agents really learning?
1:08:00 - How many silly rules are optimal?
1:11:30 - Why do you have separate weights for each agent?
1:13:45 - What features could be added next?
1:16:00 - How sensitive is the system to hyperparameters?
1:17:20 - How to avoid confirmation bias?
1:23:15 - How does this play into progress towards AGI?
1:29:30 - Can we make real-world recommendations based on this?
1:32:50 - Where do we go from here?
Paper: https://www.pnas.org/doi/10.1073/pnas...
Blog: https://deepmind.com/research/publica...
Abstract:
The fact that humans enforce and comply with norms is an important reason why humans enjoy higher levels of cooperation and welfare than other animals. Some norms are relatively easy to explain; they may prohibit obviously harmful or uncooperative actions. But many norms are not easy to explain. For example, most cultures prohibit eating certain kinds of foods and almost all societies have rules about what constitutes appropriate clothing, language, and gestures. Using a computational model focused on learning shows that apparently pointless rules can have an indirect effect on welfare. They can help agents learn how to enforce and comply with norms in general, improving the group’s ability to enforce norms that have a direct effect on welfare.
Authors: Raphael Köster, Dylan Hadfield-Menell, Richard Everett, Laura Weidinger, Gillian K. Hadfield, Joel Z. Leibo
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
13
views

First Author Interview: AI & formal math (Formal Mathematics Statement Curriculum Learning)
#openai #math #imo
This is an interview with Stanislas Polu, research engineer at OpenAI and first author of the paper "Formal Mathematics Statement Curriculum Learning".
Watch the paper review here: https://youtu.be/lvYVuOmUVs8
OUTLINE:
0:00 - Intro
2:00 - How do you explain the big public reaction?
4:00 - What's the history behind the paper?
6:15 - How does algorithmic formal math work?
13:10 - How does expert iteration replace self-play?
22:30 - How is the language model trained and used?
30:50 - Why is every model fine-tuned on the initial state?
33:05 - What if we want to prove something we don't know already?
40:35 - How can machines and humans work together?
43:40 - Aren't most produced statements useless?
46:20 - A deeper look at the experimental results
50:10 - What were the high and low points during the research?
54:25 - Where do we go from here?
Paper: https://arxiv.org/abs/2202.01344
miniF2F benchmark: https://github.com/openai/miniF2F
Follow Stan here: https://twitter.com/spolu
Abstract:
We explore the use of expert iteration in the context of language modeling applied to formal mathematics. We show that at same compute budget, expert iteration, by which we mean proof search interleaved with learning, dramatically outperforms proof search only. We also observe that when applied to a collection of formal statements of sufficiently varied difficulty, expert iteration is capable of finding and solving a curriculum of increasingly difficult problems, without the need for associated ground-truth proofs. Finally, by applying this expert iteration to a manually curated set of problem statements, we achieve state-of-the-art on the miniF2F benchmark, automatically solving multiple challenging problems drawn from high school olympiads.
Authors: Stanislas Polu, Jesse Michael Han, Kunhao Zheng, Mantas Baksys, Igor Babuschkin, Ilya Sutskever
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
9
views

OpenAI tackles Math - Formal Mathematics Statement Curriculum Learning (Paper Explained)
#openai #math #imo
Formal mathematics is a challenging area for both humans and machines. For humans, formal proofs require very tedious and meticulous specifications of every last detail and results in very long, overly cumbersome and verbose outputs. For machines, the discreteness and sparse reward nature of the problem presents a significant problem, which is classically tackled by brute force search, guided by a couple of heuristics. Previously, language models have been employed to better guide these proof searches and delivered significant improvements, but automated systems are still far from usable. This paper introduces another concept: An expert iteration procedure is employed to iteratively produce more and more challenging, but solvable problems for the machine to train on, which results in an automated curriculum, and a final algorithm that performs well above the previous models. OpenAI used this method to even solve two problems of the international math olympiad, which was previously infeasible for AI systems.
OUTLINE:
0:00 - Intro
2:35 - Paper Overview
5:50 - How do formal proofs work?
9:35 - How expert iteration creates a curriculum
16:50 - Model, data, and training procedure
25:30 - Predicting proof lengths for guiding search
29:10 - Bootstrapping expert iteration
34:10 - Experimental evaluation & scaling properties
40:10 - Results on synthetic data
44:15 - Solving real math problems
47:15 - Discussion & comments
Paper: https://arxiv.org/abs/2202.01344
miniF2F benchmark: https://github.com/openai/miniF2F
Abstract:
We explore the use of expert iteration in the context of language modeling applied to formal mathematics. We show that at same compute budget, expert iteration, by which we mean proof search interleaved with learning, dramatically outperforms proof search only. We also observe that when applied to a collection of formal statements of sufficiently varied difficulty, expert iteration is capable of finding and solving a curriculum of increasingly difficult problems, without the need for associated ground-truth proofs. Finally, by applying this expert iteration to a manually curated set of problem statements, we achieve state-of-the-art on the miniF2F benchmark, automatically solving multiple challenging problems drawn from high school olympiads.
Authors: Stanislas Polu, Jesse Michael Han, Kunhao Zheng, Mantas Baksys, Igor Babuschkin, Ilya Sutskever
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
22
views
![[ML News] DeepMind controls fusion | Yann LeCun's JEPA architecture | US: AI can't copyright its art](https://hugh.cdn.rumble.cloud/s/s8/1/r/W/t/s/rWtsd.oq1b.2-small-ML-News-DeepMind-controls-f.jpg)
[ML News] DeepMind controls fusion | Yann LeCun's JEPA architecture | US: AI can't copyright its art
#mlnews #deepmind #fusion
Updates on what's going on in the ML world!
Check out w&b's alerts feature: https://wandb.me/yannic
OUTLINE:
0:00 - Intro
0:20 - Sponsor: Weights & Biases
2:35 - DeepMind uses Reinforcement Learning to control nuclear fusion
4:35 - Google responds to carbon emission estimates
8:40 - Yann LeCun proposes new architecture for world models
11:05 - Fruit fly neurons may perform multiplication
12:00 - Emojisearch App
12:30 - Ar5iv officially in arXiv labs
12:55 - Language Model Consciousness & Media Hype
16:45 - Vision models are more fair when trained on uncurated data
18:30 - CLIPasso
19:15 - NLP with Transformers Book
20:15 - Helpful Things
26:00 - US Office: AI can't copyright its art
Sponsor: Weights & Biases
https://wandb.me/yannic
References:
https://wandb.me/yannic
DeepMind uses RL to control nuclear fusion
https://deepmind.com/blog/article/Acc...
https://www.nature.com/articles/s4158...
https://www.nature.com/articles/s4158...
https://www.alexirpan.com/2018/02/14/...
Google responds to carbon emission estimates
https://ai.googleblog.com/2022/02/goo...
Yann LeCun proposes new architecture for world models
https://ai.facebook.com/blog/yann-lec...
Fruit fly neurons may perform multiplication
https://www.nature.com/articles/s4158...
Emojisearch App
https://twitter.com/lilianweng/status...
https://www.emojisearch.app/
https://github.com/lilianweng/emoji-s...
Ar5iv officially in arXiv labs
https://blog.arxiv.org/2022/02/21/arx...
Tech media may be only slightly conscious
https://twitter.com/ilyasut/status/14...
https://futurism.com/the-byte/openai-...
https://interestingengineering.com/ai...
https://futurism.com/mit-researcher-c...
https://www.dailymail.co.uk/sciencete...
https://futurism.com/conscious-ai-bac...
https://www.dailystar.co.uk/tech/news...
Vision models are more fair when trained on uncurated data
https://arxiv.org/pdf/2202.08360.pdf
CLIPasso
https://clipasso.github.io/clipasso/
NLP with Transformers Book
https://www.amazon.de/dp/1098103246?l...
Helpful Things
https://github.com/j3soon/tbparse
https://github.com/openvinotoolkit/an...
https://liuliu66.github.io/articulati...
https://github.com/RobertTLange/evosax
https://github.com/google/evojax
https://github.com/google/evojax/pull/9
https://github.com/facebookresearch/t...
https://standard-ai.github.io/Standar...
https://twitter.com/PatrickPlaten/sta...
https://aimagelab.ing.unimore.it/imag...
https://github.com/yashbhalgat/HashNe...
https://github.com/patrick-kidger/dif...
https://github.com/AI4Finance-Foundat...
https://huggingface.co/AI-Nordics/ber...
https://huggingface.co/AI-Nordics/gpt...
https://paperswithcode.com/dataset/muld
https://github.com/JonasGeiping/breac...
https://github.com/Weixin-Liang/MetaS...
US Office: AI can't copyright its art
https://www.theverge.com/2022/2/21/22...
https://www.urbasm.com/2016/05/artifi...
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
42
views

AlphaCode - with the authors!
An interview with the creators of AlphaCode!
Paper review video here: https://youtu.be/s9UAOmyah1A
OUTLINE:
0:00 - Intro
1:10 - Media Reception
5:10 - How did the project go from start to finish?
9:15 - Does the model understand its own code?
14:45 - Are there plans to reduce the number of samples?
16:15 - Could one do smarter filtering of samples?
18:55 - How crucial are the public test cases?
21:55 - Could we imagine an adversarial method?
24:45 - How are coding problems even made?
27:40 - Does AlphaCode evaluate a solution's asymptotic complexity?
33:15 - Are our sampling procedures inappropriate for diversity?
36:30 - Are all generated solutions as instructive as the example?
41:30 - How are synthetic examples created during training?
42:30 - What were high and low points during this research?
45:25 - What was the most valid criticism after publication?
47:40 - What are applications in the real world?
51:00 - Where do we go from here?
Paper: https://storage.googleapis.com/deepmi...
Code: https://github.com/deepmind/code_cont...
Abstract: Programming is a powerful and ubiquitous problem-solving tool. Developing systems that can assist programmers or even generate programs independently could make programming more productive and accessible, yet so far incorporating innovations in AI has proven challenging. Recent large-scale language models have demonstrated an impressive ability to generate code, and are now able to complete simple programming tasks. However, these models still perform poorly when evaluated on more complex, unseen problems that require problem-solving skills beyond simply translating instructions into code. For example, competitive programming problems which require an understanding of algorithms and complex natural language remain extremely challenging. To address this gap, we introduce AlphaCode, a system for code generation that can create novel solutions to these problems that require deeper reasoning. Evaluated on recent programming competitions on the Codeforces platform, AlphaCode achieved on average a ranking of top 54.3% in programming competitions with more than 5,000 participants. We found that three key components were critical to achieve good and reliable performance: (1) an extensive and clean competitive programming dataset for training and evaluation, (2) large and efficient-to-sample transformer-based architectures, and (3) large-scale model sampling to explore the search space, followed by filtering based on program behavior to a small set of submissions.
Authors: Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushmeet Kohli, Nando de Freitas, Koray Kavukcuoglu and Oriol Vinyals
Links:
Merch: store.ykilcher.com
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
15
views
![[ML News] Uber: Deep Learning for ETA | MuZero Video Compression | Block-NeRF | EfficientNet-X](https://hugh.cdn.rumble.cloud/s/s8/1/a/j/i/l/ajild.oq1b.2-small-ML-News-Uber-Deep-Learning-.jpg)
[ML News] Uber: Deep Learning for ETA | MuZero Video Compression | Block-NeRF | EfficientNet-X
#mlnews #muzero #nerf
Your regularly irregular updates on everything new in the ML world!
Merch: store.ykilcher.com
OUTLINE:
0:00 - Intro
0:15 - Sponsor: Weights & Biases
2:15 - Uber switches from XGBoost to Deep Learning for ETA prediction
5:45 - MuZero advances video compression
10:10 - Learned Soft Prompts can steer large language models
12:45 - Block-NeRF captures entire city blocks
14:15 - Neural Architecture Search considers underlying hardware
16:50 - Mega-Blog on Self-Organizing Agents
18:40 - Know Your Data (for Tensorflow Datasets)
20:30 - Helpful Things
Sponsor: Weights & Biases
https://wandb.me/yannic
References:
https://docs.wandb.ai/guides/integrat...
https://colab.research.google.com/git...
https://wandb.ai/borisd13/GPT-3/repor...
Uber switches from XGBoost to Deep Learning for ETA prediction
https://eng.uber.com/deepeta-how-uber...
MuZero advances video compression
https://deepmind.com/blog/article/MuZ...
https://storage.googleapis.com/deepmi...
Learned Soft Prompts can steer large language models
https://ai.googleblog.com/2022/02/gui...
https://aclanthology.org/2021.emnlp-m...
Block-NeRF captures entire city blocks
https://arxiv.org/abs/2202.05263
https://arxiv.org/pdf/2202.05263.pdf
https://waymo.com/intl/zh-cn/research...
Neural Architecture Search considers underlying hardware
https://ai.googleblog.com/2022/02/unl...
https://openaccess.thecvf.com/content...
Mega-Blog on Self-Organizing Agents
https://developmentalsystems.org/sens...
https://flowers.inria.fr/
Know Your Data (for Tensorflow Datasets)
https://knowyourdata-tfds.withgoogle....
https://knowyourdata.withgoogle.com/
Helpful Things
https://twitter.com/casualganpapers/s...
https://www.reddit.com/r/MachineLearn...
https://arxiv.org/abs/2202.02435
https://github.com/vicariousinc/PGMax
https://www.vicarious.com/posts/pgmax...
https://diambra.ai/tournaments
https://github.com/diambra/diambraArena
https://www.youtube.com/watch?v=dw72P...
https://gitlab.com/deepcypher/python-...
https://python-fhez.readthedocs.io/en...
https://joss.theoj.org/papers/10.2110...
https://github.com/PyTorchLightning/m...
https://torchmetrics.readthedocs.io/e...
https://twitter.com/alanyttian/status...
https://github.com/google/evojax
https://arxiv.org/abs/2202.05008
https://www.reddit.com/r/MachineLearn...
https://www.gymlibrary.ml/pages/api/#...
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
27
views